Here you can find information, how to measure speed of your machine running spinpack.
First you have to download spinpack-2.34.tgz (or better version). Uncompress and untar the file, configure the Makefile, compile the sources and run the executable. Here is an example:
gunzip -c spinpack-2.34.tgz | tar -xf -
cd spinpack
./configure --mpt # configure for pthreads (and/or --mpi for MPI)
make speed_test # compile spinpack, create data files
cd exe
# choose problem size by setting nud (matrix in memory):
# nud=10,30 - 1MB memory, 30MB disk ca. 5-45m (summed time)
# nud=12,28 - 7GB memory, 180MB disk ca. 3-5h (summed time, default)
# nud=14,26 - 43GB memory, 1GB disk ca.18-30h (summed time)
# for MPI: please reduce B_NUM in config.h and re-make if .bss is to big
nedit daten.i
# start with 1,2,...16 threads (or/and use mpirun)
for x in 1 2 4 8 16; do ./spin -t$x; done 2>&1 | tee -a o_speed
Send me the output files together with the characteristic data
of your computer for comparisions. Please also add the output of
grep FLAGS= Makefile if you have. If you need some help,
you can send me an EMail.
Since version 2.31 it is possible to tune the data chunks to be transfered per MPI (HBLen for i100-time, NUM_AHEAD_LINES for SH-time) or the caching behavior on SMP machines. Overloading an SMP node with threads could also be usefull, but will consume more memory for MPI caching. In that case BNUM defined in config.h determines the maximum number of threads which can be set to any smaller value by -t option.
The next tables give an overview about computation time for a N=40 site system (used for speed test) started at year 2003 and later. First column marks the up- and down-spins (nu,nd) given in daten.i. These numbers define the size of the problem (nn!/(nu!nd!(4nn))) with nu+nd=nn. Other columns list the time needed for writing the matrix (SH) and for the first 40 iterations (i=40) (old version) or the extrapolated time for the first 100 iterations (version 2.27) showed by the output. For the new version ns is the time for filtering symmetric configurations and 12sisj the time for computing the correlations. ns and 12sisj are not important for the actual speed measurements.
new tests: (verbose=1, SBase=1, S1sym=1(?), dbl) # Altix330IA64-1500MHz 8nodes*2IA64.m2.r1 maxN2N_BW=6.4GB/s (slow int div) # MPT-MPI-1.2 (insmod xpmem) MPI_USE_XPMEM=1 MPI_XPMEM_VERBOSE=1 # MPI_DSM_CPULIST=0,1,... # numactl -l mpi_speed -np 2: 1.43us 13.4GB/s, 4: 3.10us 23GB/s nud CPUs ns SH i100 12sij machine time=min[:ss] dflt: v2.26 -O2 ------+---+-------------------------------------------------- 10,30 1*1 0.40 11.20 38.87 - v2.31 Hsize=1.5MB,38.87m 96K,33m 10,30 2*1 0.40 6.08 28.63 - v2.31 10,30 4*1 0.40 3.47 25.13 - v2.31 10,30 8*1 0.40 1.80 20.40 - v2.31 39%mpi Hsize=1.5MB,20.4m 96kB,18m 96-to-32bit=10.15m(div2mul=-70%) 2e6,5..8GB-send 10,30 8*1 0.40 1.87 8.37 - v2.31 int div and mod reduced 10,30 12*1 0.40 1.30 18.48 - v2.31 Hsize=96kB,15.37m 192kB,15.48m 1.5MB,18.48m 10,30 14*1 0.40 1.15 16.12 - v2.31 10,30 1*2 0.40 6.05 22.80 - v2.31 10,30 2*2 0.40 3.28 19.58 - v2.31 10,30 4*2 0.40 1.92 16.25 - v2.31 10,30 6*2 0.40 1.32 14.30 - v2.31 10,30 1*4 0.40 3.30 14.53 - v2.31 10,30 2*4 0.40 1.90 10.47 - v2.31 10,30 1*8 0.40 1.72 9.00 - v2.31 Hsize=1.5MB,9.00m 96kB,6.87m 30,10 1 6.65 19.25 12.90 - v2.27p6-flt gcc4.1-O2 30,10 2 4.18 9.90 10.28 - v2.27p6 113MB + 840MB 30,10 4 2.55 4.92 6.33 - v2.27p6 30,10 8 2.48 2.68 4.42 - v2.27p6 30,10 8 1.88 2.40 4.15 - v2.27p6 gcc4.1-O3 30,10 8 1.30 1.57 3.45 - v2.27p7-flt gcc4.1-O3 6 2 -2 6 Hsize=7 sym_k=-4 0 -22 0 -2 0, +2users 28,12 1 42:13 131:21 108:02 1429:57 inlined_h_get (157m -> 108m) 28,12 2 26:15 70:32 89:55 736:00 h_get_inlined (292m -> 90m) 28,12 4 16:33 36:05 79:55 372:54 h_get_inlined (346m -> 80m) 28,12 8 16:07 19:08 38:07 190:28 h_get_inlined (412m -> 38m) # v2.23 bad scaling i100+SH (h_get not inlined), but SH-singlespeed # 28,12 16 18 40.2 61.0 - Altix330-gcc-3.3-O2 v2.23 hxy_size 163840/32768=5 14+2CPUs auf 1RAM, numalink=Bottleneck # 28,12 8 18 34.6 145.0 - Altix330-gcc-3.3-O2 v2.23 hxy_size 163840/32768=5 # 28,12 4 18 44.4 218.3 - Altix330-gcc-3.3-O2 v2.23 hxy_size 163840/32768=5 # 28,12 2 28 62.0 294.8 - Altix330-gcc-3.3-O2 v2.23 hxy_size 163840/32768=5 # 28,12 1 46 94.4 146.2 - Altix330-gcc-3.3-O2 v2.23 hxy_size 163840/32768=5 20,20 15 366. 455. 11550. - v2.26-flt J2=0.59 q_10_10_0_0- n2.char=0/50m PentiumM-600MHz L1D=32kB,1465MB/s L2=1MB,714MB/s mem=2GB,168MB/s FSB=4*100MHz SSE2 fam=6 model=9 stepping=5 nud CPUs ns SH i100 12sij machine time=min dflt: v2.26 -O2 ------+--++------------------------------------ default=160sym 32,8 1 1.48 4.82 2.17 45.72 gcc4.1-v2.27p5-Oct07 32,8 1 1.4 4.2 2.8 gcc4.1-v2.27p5 STOREH=4 fread(buffered) 32,8 1 1.4 3.9 2.5 gcc4.1-v2.27p5 STOREH=0 mem 32,8 1 1.4 4.3 2.5 gcc4.1-v2.27p5 STOREH=2 read-unbufered 32,8 1 1.4 3.9 1.1 gcc4.1-v2.27p5 STOREH=0 mem b_getnum=removed 32,8 1 1.4 3.9 1.4 gcc4.1-v2.27p5 STOREH=0 mem b_getnum(pt_n) 32,8 1 1.45 4.02 0.92 gcc4.1-v2.27p7 STOREH=0 no_memcpy 32,8 8 1.5 4.3 2.1 gcc4.1-mtune=pentium4-msse2 i2b=integer-division 32bit 8,32 1 0.07 4.17 1.97 gcc4.1-v2.27p7 STOREH=0 j1j2 8,32 1 0.08 4.08 1.97 gcc4.1-v2.27p7 STOREH=0 XandY j1j2 FLOPS=(100(2hnz+9n1)=6333n1=3.05e9)/66s=46MFLOPS=15%peak(=clk/2) BW=(100(24hnz+24n1)=67584n1=32.6e9)/66s=494MB/s=69%L2speed P4-1.3GHz Northwood FSB=4*100MHz L1D=8kB,10.6GB/s L2=512kB,9GB/s 1GB,1.2GB/s SSE2 HT fam=15 model=2 stepping=9 mem=233MHz nud CPUs ns SH i100 12sij machine time=min dflt: v2.26 -O2 ------+--++------------------------------------ default=160sym -8.22686824 # HBLen=16K i100=1.12, HBLen=8K,4K,1K,128 i100=1.13(2i100=1.08) 8,32 1*2 0.08 1.05 2.27 - MPI!100%local+ 0%mpi 2.28 8,32 1*1 0.08 1.38 2.42 - MPI!100%local+ 0%mpi 2.28 8,32 2*1 0.08 2.32 63.42 - MPI! 80%local+20%mpi 2.28 HT+noAHEAD 8,32 1*2 0.05 1.23 1.77 - MPI!100%local+ 0%mpi 2.34+ 8,32 1*1 0.05 1.63 2.10 - MPI!100%local+ 0%mpi 2.34+ 8,32 2*1 0.08 1.33 2.43 - MPI! 80%local+20%mpi 2.34+ HT 32,8 1 0.83 2.58 1.48 - P4-1.3GHz-gcc4.1-v2.26 32,8 2 0.70 1.93 1.33 - P4-1.3GHz-gcc4.1-v2.26 32,8 1 0.40 1.27 1.00 - P4-2.6GHz-gcc4.1-v2.26 32,8 2 0.35 1.07 0.82 - P4-2.6GHz-gcc4.1-v2.26 Hyper-Threading(2x) sse2 32,8 4 0.35 0.98 0.82 10.12 32,8 1 0.40 8.80 0.78 - -mtune=pentium4 -msse2 new b_smallest.v2.17a 32,8 1 0.40 0.78 0.60 t_sites=int,float 10% speedup 32,8 2 23.88 69.87 16.20 - callgrind --trace-children=yes callgrind_annotate Ir-recorded: sum 249e9 b_smallest=114e9+15e9 b_ifsamllest3=62e9 30,10 1 8.57 32.02 41.78 - P4-1.3GHz-gcc4.1-v2.26 30,10 2 7.27 23.68 37.00 - P4-1.3GHz-gcc4.1-v2.26 Intel-Core2-Quad-2.40GHz fam=6 mod=15 step=7 L2=4M board=ICH9 ri_boson 2007/12 # k2.6.22.5 mem=8GB nud CPUs ns SH i100 12sij machine time=min ------+--++-------------------------------- n1=5.3e6 113MB+840MB E=-13.57780124 12,28 1 1.48 42.95 38.83 - v2.31+ gcc-4.2 12,28 2 1.50 22.75 23.92 - v2.31+ sh=20.27..22.75 12,28 4 1.50 12.02 17.35 - v2.31+ sh=9.80..12.02 # repeat: sh=12.02 i100=17.27..17.35 12,28 4 1.88 12.32 34 - v2.31+ STOREH=4 dd=75..77MB/s nud CPUs ns SH i100 12sij machine time=min dflt: v2.27 -O2 ------+--++-------------------------------- n1=5.3e6 113MB+840MB E=-13.57780124 30,10 2 1.68 5.72 4.27 57.78 Xeon-E5345-2.33Ghz-2*4MB-gcc4.1-v2.27 32GB thor 30,10 4 1.32 2.92 2.97 29.15 Clovertown 2,33 GHz FSB1333 80Watt 851$ 30,10 8 1.07 1.47 2.67 14.72 chipset i5000P totBW=21GB/s 30,10 8 1.02 1.47 2.25 14.68 flt 28,12 1 14.90 78.78 58.78 808.77 Xeon-E5345-2.33Ghz-2*4MB-gcc4.1-v2.27 32GB thor k2.6.18 28,12 2 10.35 40.88 35.10 411.73 28,12 4 7.92 20.90 25.35 208.82 28,12 8 6.15 10.58 22.48 105.62 28,12 8 6.13 10.60 19.48 105.33 flt tina-beowulf: 2Xeon(HT2)3Ghz.5MB-gcc4.1 2GB eth100Mb 160-200us 15-63MB/s # latency=200us equivalent to transfer of 63MB/s*200us=12.6kB, ppn=2..4 # Feb08: nodes=64:ppn=1 237us 536MB/s(16M) OpenMPI-1.2.5 # bei ppn=2 Mix of HT(CMT) and 2-CPU-runs (random use of virt. CPU0..3) nud mpi*CPUs ns SH i100 12sij machine=tina time=min ------+--++-------------------------------- n1=5.3e6 113MB+840MB E=-13.57780124 8,32 1 0.02 0.58 1.53 . v2.30-dbl-dbg 8,32 2*2 0.02 0.23 4.58 . v2.31 18%mpi+13%pt 8,32 2*1 0.02 0.40 5.05 . v2.31 18%mpi AHEAD=1024 56e6/20e6/s 708*160e-6s 8,32 4*1 0.02 0.25 4.92 . v2.31 31%mpi 99e6 1060 /* mpi-transfer hnz*nzsize/mpispeed=168e6*6/(15e6..63e6/s) i100=ca.65m */ /* mpi-transfer n1*mpilatenz=5.3e6*200e-6s data=n1*NZX=5.3e6*162/30e6 SH=18m+0.65m */ 10,30 1*1 0.27 8.75 17.37 . v2.30p3-dbl 10,30 1*2 0.27 4.68 13.00 . v2.31 0%mpi 15%pt 10,30 1*4 0.27 3.30 13.70 . v2.31 0%mpi 29%pt Hyperthreading 10,30 2*1 0.27 5.65 55.03 . v2.31 15%mpi 0%pt 10,30 2*2 0.27 3.12 46.47 . v2.31 15%mpi 14%pt 64to32=45.03m 10,30 2*4 0.27 2.42 46.13 . v2.31 15%mpi 22%pt HyperThreading # ToDo: grafik CPU+Net? vmstat+netstat + output packets + MBytes transferred 10,30 4*1 0.27 3.47 60.62 . v2.31 29%mpi 0%pt 10,30 4*2 0.27 2.12 55.95 . v2.31 29%mpi 8%pt 64to32=43.75m 10,30 4*4 0.27 1.72 56.87 . v2.31 29%mpi 15%pt HyperThreading 10,30 8*1 0.27 2.10 49.52 . v2.31 37%mpi 10,30 8*2 0.27 1.33 45.90 . v2.31 37%mpi 8%pt 64to32=33.48m 10,30 8*4 0.27 1.13 46.33 . v2.31 37%mpi 13%pt 12,28 6*1 1.73 19.25 373 . v2.31 31%mpi 1GB+6GB=6*1.3GB minNodes=4 12,28 6*2 1.73 12.12 341.10 . v2.31 31%mpi us=26% sy=13% id=62% (4th) 12,28 6*2 1.73 12.13 151.78 . v2.31+ float 32MB/s HSize=24MB + token-double-ring # 12,28 6*2 1.77 10.30 89.93 . v2.31+ float 60MB/s 31%mpi 8%pt flt ppn=1 tpn=2 HSize=25M Feb08 new # 12,28 15*2 1.80 5.50 57.22 . v2.31+ float 125MB/s 41%mpi 5%pt flt ppn=1 tpn=2 HSize=25M Feb08 new # leonardo.nat-cluster 14*(2iXeon3GHz L2=512kB 4GB, 1of4Gbit) # 2nodes 46.25us 116MB/s, 8nodes 46us 680MB/s, 14nodes 52us 1240MB/s BS>=1MB # 2local 1.94us 441MB/s # SGE: qsub -j y -cwd -pe OpenMPI 8-16 -l mem=3000 ... # 3000MB nud mpi*CPUs ns SH i100 12sij time=min ------+--++-------------------------------- n1=5.3e6 113MB+840MB E=-13.577801 10,30 1*1 0.25 7.77 16.88 . v2.31+dbl # mem+hfile=1GB 10,30 2*1 0.25 4.42 14.54 . v2.31+dbl -byslot AHEAD=1k HSize=1572864 10,30 2*1 0.25 4.47 14.05 . v2.31+dbl -bynode AHEAD=1k HSize=1572864 10,30 4*1 0.25 2.47 22.67 . v2.31+dbl -bynode AHEAD=1k HSize=1572864 10,30 8*1 0.25 1.35 18.87 . v2.31+dbl -bynode AHEAD=1k HSize=1572864 10,30 1*2 0.25 4.33 11.62 . v2.31+dbl B_NUM=64 NZX=162 AHEAD=1k HSize=1572864 10,30 2*2 0.25 2.40 9.55 . v2.31+dbl B_NUM=64 NZX=162 AHEAD=1k HSize=1572864 10,30 4*2 0.25 2.18 19.25 . v2.31+dbl B_NUM=64 NZX=162 AHEAD=1k HSize=1572864 10,30 8*2 0.25 0.78 17.58 . v2.31+dbl NZXMAX 42 + NUM_AHEAD_LINES 8192 10,30 12*2 0.25 0.60 14.47 . v2.31+dbl B_NUM=2 ToDo: warn BNUM>2 ??? 10,30 12*2 0.25 0.60 14.42 . v2.31+dbl NZXMAX 42 + NUM_AHEAD_LINES 8192 # ibio-cc 25*(DualCore-AMD2214-2.2GHz-1MB 4GB) # mpich-1.2.7: 4 52us 159MB/s(1M) (eth0 only) # 16 53us 582MB/s(16M) (eth0 only) # lam-7.1.2: # mpicc linker error for edg in modeldef.c # igetcl2-cluster: 10* 4GB 2Xeon(HT)-2.8GHz-512kB eth0-100Mb eth1,2-1Gb # cpu-family=15 model=2 stepping=7 kein flag=lm (long mode), 32bit k2.4.27 # 2nodes 290us 159MB/s, 8nodes 336us 636MB/s, 10nodes 353us 750MB/s(1MB) 784MB/s(8MB) # --mca btl_tcp_if_include eth1 OpenMPI-1.2.3 # 10nodes (latency eth1=eth2 341us 643MB/s(.5MB) 679MB/s(1MB)) nud mpi*CPUs ns SH i100 12sij machine=igetcl2 time=min ------+--++-------------------------------- n1=5.3e6 113MB+840MB E=-13.57780124 8,32 1 0.02 0.62 1.30 . v2.31-dbl 8,32 2*1 0.02 0.35 1.63 . v2.31 18%mpi 8,32 2*2 0.02 0.27 1.78 . v2.31 18%mpi+13%pt 10,30 1*1 0.30 9.18 18.33 v2.31-dbl 10,30 1*2 0.30 4.98 13.30 v2.31 0%mpi 15%pt 10,30 2*1 0.30 5.07 23 v2.31 15%mpi 0%pt 10,30 2*2 0.30 2.77 16 v2.31 15%mpi 14%pt 10,30 4*2 0.30 1.60 16 v2.31 29%mpi 8%pt 10,30 8*2 0.30 1.05 14 v2.31 37%mpi 8%pt sys=32% 1K,192kB 10,30 8*2 0.30 0.93 9 v2.31 37%mpi 8%pt sys=32% 4K,1.5MB B_NUM=2 10,30 8*1 0.30 1.62 21 v2.31 37%mpi sys=50-70% 10,30 10*1 0.30 1.45 21 ? v2.31 sys=5%, us=13% sy=14% id=73% unbalanced 10,30 10*2 0.30 0.97 14 ? v2.31 sys=9%, us=23% sy=21% id=56% unbalanced 10,30 10*4 0.30 1.33 14 ? v2.31 sys=9%, us=26% sy=21% id=52% unbalanced # MPI traffic[Byte]= 1.57e+09 syncs= 1.40e+04 t=3s+4s *100=12m # print out good estimations! const/define?, SH-balance SHmin,maxMPI? # ifconfig eth1+eth2 traffic? node1-rechnet pconcept 65%systemlast (no-eth) # test lam? nud CPUs ns SH i100 12sij machine time=min dflt: v2.25 -O2 ------+--++------------------------------------ E=-8.22686823 SMag= 0.14939304 ---------------------- 28,12 1 19 54.32 96.0 - 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 28,12 2 13 32.70 83.16 - 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 28,12 4 7 19.67 96.33 - 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) memory distributed badly? k2.6.9 (2.6.18 is faster) 28,12 4 9.22 24.22 30.6 - 2CoreOpteron-2194MHz-gcc-4.1 v2.27 k2.6.18 28,12 1 30.00 47.68 70.50 - 4xDualOpteron885-2600MHz-gcc-4.0 64bit n2=32:15 (7m03s/10It) kanotix2005-04-64bit 16G-RAM tmpfs DL585 28,12 2 22.00 30.32 66.00 - 4xDualOpteron885-2600MHz-gcc-4.0 64bit n2=24:03 kanotix2005-04-64bit 16G-RAM tmpfs 28,12 4 16.92 16.48 35.00 ns? 4xDualOpteron885-2600MHz-gcc-4.0 64bit n2=13:27 kanotix2005-04-64bit 16G-RAM tmpfs 28,12 8 8.48 9.02 21.60 - 4xDualOpteron885-2600MHz-gcc-4.0 64bit n2=10:18 kanotix2005-04-64bit 16G-RAM tmpfs 12,28 4 1.85 13.65 20.22 numactl -C 2,4,5,7 4xDualOpteron885-2600MHz-gcc-4.1 v2.31+ SLES10-amd64 (sh=5.40..7.03) STOREH=0 8GB comp1 12,28 4 1.85 12.22-24.95 20.88 numactl -C 1-5 4xDualOpteron885-2600MHz-gcc-4.1 v2.31+ SLES10-amd64 (sh=5.40..7.03) STOREH=0 8GB comp1 # i100 bus collisions? 12,28 8 1.85 7.03 22.85 4xDualOpteron885-2600MHz-gcc-4.1 v2.31+ SLES10-amd64 (sh=5.40..7.03) STOREH=0 8GB comp1 nud CPUs ns SH i100 12sij [min] dflt: v2.26 -O2 ------+--+------------------------------ 30,10 1 4.78 30.72 14.17 - V490-32GB 4x2-sparcv9-ultraIV+-10*150MHz-2MB/32MB(L3)-gcc4.1 L1=64K+64K 30,10 2 3.60 15.53 8.15 - J2=0? gcc-4.1 -O2 30,10 4 1.82 7.82 4.57 - 30,10 8 1.48 3.97 3.18 - 30,10 16 1.50 3.95 3.38 - 30,10 32 1.43 3.90 3.57 - 28,12 1 29.98 205.30 143.72 - 28,12 2 22.17 104.67 82.75 - 28,12 4 11.10 53.20 46.50 - 28,12 8 9.55 26.80 31.77 - 28,12 16 9.63 26.70 33.68 - 28,12 32 9.33 26.82 35.52 - M4000 4*DualCore*2threads-Fujitsu-SPARC64-VI-2150MHz L2=5MB 32GB SClk=1012MHz ray4.ub maxBW=32GB/s nud CPUs ns SH i100 12sij [min] dflt: v2.26 -O2 ------+--+------------------------------ 30,10 1 3.57 12.92 11.10 - SunM4000 4chips*2cores*2threads-2.15GHz 30,10 2 2.45 6.75 7.10 30,10 4 1.30 3.50 4.55 30,10 8 1.13 1.82 3.80 - v2.26 CC-5.3-fast-xtarget=ultra4 30,10 16 1.13 1.67 3.05 - CMT 30,10 16 1.12 1.70 3.13 - v2.27p5 CC-5.3-fast-xtarget=ultra4 # SunFire-T200-8GB 8x4-ultraSparc-T1-5*200MHz-3MB?-gcc-4.1-flt L1=8K+16K # ToDo: better compiler[options]? ------+---+-------+--------+--------+-------- 30,10 1 18.05 64.25 72.63 663.07 30,10 2 11.62 32.48 39.60 341.27 n2.t=1.33 30,10 4 6.68 16.35 21.63 174.22 30,10 8 6.52 8.33 13.87 90.83 n2.t=1.33 4CPUs-ab70s 1cpu-ab200s 30,10 16 6.53 5.57 10.50 59.42 30,10 32 6.53 4.68 9.08 48.85 sh=96% cat_htmp*=0.02s 28,12 8 42.40 59.90 129.18 625.87 28,12 32 42.37 32.02 103.48 - ns=(+1m=25%,+19m=88m) dd=7GB/14s nud CPUs ns SH i100 12sij machine time=min dflt: v2.26 -O2 ------+--++--------------------------------- psrinfo-v EV6.7 (21264A) 30,10 1 6:24 32:29 38:02 - GS160-24GB 4x4-alpha-731MHz v2.26 cxx-6.5 30,10 2 4:38 16:47 25:30 - 30,10 4 3.40 8.73 21.02 - 2.27 empty machine Apr07 30,10 8 2.68 4.55 13:17 - 2.27 empty machine Apr07 30,10 16 2.08 2.30 7.58 - 2.27 empty machine Apr07 28,12 4 20.50 65.73 182.93 - 2.27 empty machine Apr07 28,12 8 16.07 34.17 112.45 - 2.27 empty machine Apr07 28,12 16 12.45 18.28 65.58 - 2.27 empty machine Apr07 *32,8 8 0.20 21.20 83.40 113.58 # 820sisj 1sym! 2.27 Apr07 n1=77e6 # ES45-4ev68-1.25GHz CC6.5-fast STORE=0 (mima) # MPI cpus,latency,bandwitdh= 2 2.62us 811MB/s, 3 2.49us 880MB/s, 4 2.79us 3.65GB/s nud CPUs ns SH i100 12sij machine time=min -------+--++---------------------------------- psrinfo -v EV6.8 (21264C) L2=16MB 1.25GHz # nu,nd cpus AHEAD traffic=12*hnz*mpi% syncs=n1/AHEAD # ToDo: mpi_ofs[mpi_n] + pt_ofs[pt_n] + mpi_len..., # v[pt_n] -> v[pt_ofs[]+i] faster? (two versions per ifdef) # locality per mpi! no block lists to transfer (simpler code) # if (pt_n>1) mutex, SH: send back only jj[n] and rx sh.t-12% # n1=5.3e6 hnz=32n1 mpi=30%(4) sh=tbase+int+long+dbl+long(25..36B) i=int+dbl(12B) 10,30 1*4 0.47 3.50 8.20 - v2.31+ 30%pt 7.1..7.5..8.25m flt=6.25m 10,30 1*2 0.47 6.73 13.22 - v2.31+ 16%pt 10,30 1*1 0.47 12.68 21.72 - v2.30 10,30 2*1 0.47 6.70 17.63 - v2.31 16%mpi 10,30 3*1 0.47 4.63 10.95 v2.31+ 24%mpi 10,30 4*1 0.47 3.50 9.33 - v2.31+ 30%mpi*1.9GB/3.6GB/s=1/6s flt=7.75m 10,30 2*2 0.47 3.50 9.20 - v2.31+ 10,30 1 0.47 12.60 20.53 - v2.29p1 10,30 2 0.47 6.77 12.83 - v2.29p1 10,30 4 0.47 3.60 7.50 - v2.29p1 10,30 4 0.47 14.25 15.27 - v2.34+ AH=16K HB=32K 10,30 4 0.47 7.68 10.37 - v2.34+ AH=16K HB=32K (NZX independent) 10,30 4 0.47 4.00 6.22 - v2.34+ AH=16K HB=32K balance=88% 10,30 4 0.47 4.00 6.12 - v2.34+ AH=16K HB=2K balance=88% 10,30 4 0.47 4.00 6.03 - v2.34+ AH=16K HB=1K balance=88% 10,30 4 0.47 4.00 7.03 - v2.34+ AH=16K HB=832 balance=88% 10,30 4 0.47 4.00 6.00 - v2.34+ AH=16K HB=768 balance=88% 10,30 4 0.47 4.00 6.08 - v2.34+ AH=16K HB=512 balance=88% 10,30 4 0.47 4.02 6.48 - v2.34+ AH=16K HB=256 balance=88% 10,30 4 0.47 4.02 6.40 - v2.34+ AH=16K HB=128 balance=88% # ToDo: grafik for min/max speed(AH,HB) ?? 10,30 4 0.47 4.42 6.25 - v2.34+ AH=1 HB=32K 10,30 4 0.47 3.87 11 - v2.34+ AH=16K HB=768 balance=88% MPI! 10,30 4 0.47 3.77 10 - v2.34+ AH=16K HB=32K balance=88% MPI! 30,10 1 4.03 20.48 13.45 - v2.27p6 30,10 2 3.02 10.57 8.97 30,10 4 2.33 5.33 5.37 30,10 8 2.12 5.22 5.13 - 2*overload 30,10 16 1.82 5.23 5.00 - 4*overload 30,10 32 1.45 5.18 4.95 - 8*overload E=-13.57780124 # ToDo: -arch host (ev67) # DBG: -check -verbose -check_bounds # Unaligned access: -assume noaligned_objects i100=7.00m (+30%) # GS1280-128GB-striped 32-alpha-1150MHz psrinfo -v EV7 (21364) # L1=2*64KB L2-1.75MB= mem=4GB/CPU=82..250ns cxx-6.5 nud CPUs ns SH i100 12sij machine time=min dflt: v2.27 -fast -------+--++---------------------------------- psrinfo -v EV7 (21364) 30,10 1 3.82 20.03 19.27 - # v2.27 cxx-6.5 30,10 2 2.78 10.33 11.52 - # 30,10 4 2.12 5.23 8.00 - # 2.27-dbl 0user (32cpus/rad) 30,10 8 1.68 2.67 5.18 - # 2.27-dbl 0user (32cpus/rad) + vmstat.log 30,10 16 1.30 1.35 2.83 - # 2.27-dbl 0user (32cpus/rad) 30,10 32 0.93 0.78 1.72 - # 2.27-dbl 0user (32cpus/rad) # for 32cpus/RAD memory is striped, no memory-cpu locality (see i100) 30,10 1 3.80 19.80 11.70 - # 2.27-dbl 0user (1cpus/rad) 30,10 2 2.80 10.30 7.92 - # 2.27-dbl 0user (1cpus/rad) 30,10 4 2.12 5.23 5.72 - # 2.27-dbl 0user (1cpus/rad) 30,10 8 1.67 2.67 4.33 - # 2.27-dbl 0user (1cpus/rad) + vmstat1_1cpu1rad.log i100b=4.38 30,10 16 1.28 1.37 2.85 - # 2.27-dbl 0user (1cpus/rad) i100b=2.77 30,10 32 0.92 0.68 1.75 - # 2.27-dbl 0user (1cpus/rad) # 28,12 8 10.08 18.87 37.33 - # 2.27-dbl 0user (8cpus/rad) + vmstat60-R 25%RAD2+75%RAD3 # see ps10.log CPUhopping! after crash2008/01 12,28 1 3.55 102 - # 2.31+dbl 0user (32cpus/rad) lavg=25 (user) 12,28 1 3.55 109.27 166.92 - # 2.31+dbl 0user (32cpus/rad) lavg=21 (user) 12,28 2 3.57 57.40 74.00 - # 2.31+dbl 0user (32cpus/rad) SH=52.62..57.40m balance= 18245..19471 96.7%..103.3% no_user 12,28 4 3.57 30.52 41.48 - # 2.31+dbl 0user (32cpus/rad) SH=25.85..30.52m 12,28 8 3.58 16.02 21.92 - # 2.31+dbl 0user (32cpus/rad) SH=12.80..16.02m 12,28 16 3.55 8.10 11.58 - # 2.31+dbl 0user (32cpus/rad) SH=6.23..8.10m 12,28 24 3.58 5.53 8.08 - # 2.31+dbl 0user (32cpus/rad) SH=4.17..5.53m 12,28 32 3.55 4.20 6.37 - # 2.31+dbl 0user (32cpus/rad) SH=3.08..4.20m 28,12 32 14.90 5.45 5.95 - # 2.31+dbl 0user (32cpus/rad) SH=4.48..5.45(unbalanced) STOREH=0=mem # 28,12 1 23.65 139.13 167.15 - # 2.27-dbl 0user (32cpus/rad) ps=4h33m05s real=275m 31user! 28,12 2 17.02 72.33 91.22 - # 2.27-dbl 0user (32cpus/rad) ps=4h30m47s real=152m 28,12 4 12.87 36.83 65.67 - # 2.27-dbl 0user (32cpus/rad) ps=5h24m05s real=102m 28,12 8 10.08 18.80 39.67 - # 2.27-dbl 0user (32cpus/rad 28,12 16 7.77 9.77 23.00 - # 2.27-dbl 0user (32cpus/rad) 28,12 32 5.73 4.97 13.17 - # 2.27-dbl 0user (32cpus/rad) ps=6h03m37s # 28,12 1 23.58 136.28 89.52 - # 2.27-dbl 0user (1cpus/rad) 28,12 2 17.00 71.70 59.20 - # 2.27-dbl 0user (1cpus/rad) 28,12 4 12.83 36.48 43.47 - # 2.27-dbl 0user (1cpus/rad) 28,12 8 10.07 18.63 31.17 - # 2.27-dbl 0user (1cpus/rad) + vmstat1-R(no influence to speed) 28,12 16 7.78 9.73 23.43 - # 2.27-dbl 0user (1cpus/rad) 28,12 32 5.70 4.88 13.02 - # 2.27-dbl 0user (1cpus/rad) 20,20 16 202 275 24418 - # 2.31+ SH=230..275m=4.6h i100=407h=17d 32cpus/rad file=0 old tests: (i40 is summed time for ns+n2+SH+40Iterations, bad choosen) nud CPUs SH-time i=40-time machine time=[hh:]mm:ss(+-ss) dflt: v2.15 -O2 -------+--+---------+---------+------------------------------------------ 30,10 1 23m 76m Pentium-1.7GHz-gcc v2.15 -lgz 30,10 1 21m 50m Pentium-1.7GHz-gcc v2.15 30,10 1 12:58 44:01 AthlonXP-1.7GHz-gcc-3.3 v2.21 -O4 -march=athlon-xp -m3dnow (lt=6m44s hda=48MB/s, cat 40x800MB=15m, 48%idle) 3m/5It i65:r=60m,u=34m,s=4m (also pthread) 30,10 1 15:15 38:29 AthlonXP-1.7GHz-gcc-3.2 v2.17 -O2 -march=athlon-xp -m3dnow (lt=7m29s hda=55MB/s, cat 40x800MB=15m, 40%idle) 30,10 1 15:34 45:28 AthlonXP-1.7GHz-gcc-3.2 v2.18 -O2 -march=athlon-xp -m3dnow -lgz (lt=7m29s hda=55MB/s, zcat 40x450MB=13m, 1%idle) 30,10 1 11:51 26:31 Pentium4-2.5GHz-gcc-3.2 v2.17 -O2 -march=i686 -msse B_NL2=4 30,10 1 15:59 40:09 Xeon-2GHz-gcc-3.2 v2.17 -O2 -march=i686 -msse -g -pg 30,10 1 14:26 34:08 Xeon-2GHz-gcc-3.2 v2.17 -O2 -march=i686 -msse 30,10 2 8:16 25:09 Xeon-2GHz-gcc-3.2 v2.17 -O2 -march=i686 -msse (slow nfs-disk) 30,10 1 14:40 32:26 Xeon-2GHz-gcc-3.2 v2.18 -O2 -march=i686 -msse 4x4 lt=10m34 30,10 1 8:44 16:59 Xeon-3GHz-12GB-v2.24-gcc-4.1.1 -O2 64bit 4x4 lt=3m31 model4 stepping10 n2=3m55 65s/10It 30,10 1 9:57 19:08 Xeon-3GHz- 2GB-v2.25-gcc-4.0.2 -O2 32bit 4x4 lt=4m34 model4 stepping3 n2=4m58 30,10 1 8:52 17:53 Xeon-3GHz- 2GB-v2.24-gcc-4.1.1 -O2 32bit 4x4 lt=4m25 model4 stepping3 n2=4m50 30,10 1 8:27 16:48 Xeon-2660MHz-2M/8GB-v2.25-gcc-4.1.1 amd?64bit 4x4 lt=3m43 model6 stepping4 n2=4m10 62s/10It 2*DualCore*2HT=8vCPUs bellamy 30,10 4 3:19 11:36 Xeon-2660MHz-2M/8GB-v2.25-gcc-4.1.1 amd?64bit 4x4 lt=2m10 model6 stepping4 n2=2m37 76s/10It 2*DualCore*2HT=8vCPUs bellamy 30,10 8 1:57 7:49 Xeon-2660MHz-2M/8GB-v2.25-gcc-4.1.1 amd?64bit 4x4 lt=1m07 model6 stepping4 n2=1m35 55s/10It 2*DualCore*2HT=8vCPUs bellamy 30,10 1 6:56 15:15 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=4m18 n2=04:37 (116s/10It) Knoppix-3.8-32bit 30,10 2 4:04 11:12 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=2m40 n2=02:58 (63s/10It) cpu5+7 30,10 4 2:20 9:05 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=1m39 n2=01:57 (72s/10It) cpu3-6 (2*HT dabei?) 30,10 4 2:47 6:33 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=1m23 n2=01:40 (52s/10It) cpu3-6 (2*HT dabei?) 30,10 8 1:15 4:42 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=1m37 n2=01:55 (24s/10It) 30,10 2*8 1:03 4:10 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=1m37 n2=01:55 (17s/10It) (4CPUs * 2Cores) 30,10 4*8 1:00 4:33 4xDualOpteron885-2600MHz-gcc-3.3.5 32bit lt=1m38 n2=01:56 (17s/10It) (4CPUs * 2Cores) ulimit -n 4096 30,10 2 2:43 8:57 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=1m51 n2=02:10 (46s/10It) kanotix2005-04-64bit 16G-RAM tmpfs=...MB/s 30,10 4 2:02 5:34 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=1m05 n2=01:23 (32s/10It) kanotix2005-04-64bit 16G-RAM tmpfs=...MB/s 30,10 8 1:08 3:16 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=0m42 n2=01:00 (17s/10It) kanotix2005-04-64bit 16G-RAM tmpfs 30,10 1 19:31 63:28 SunFire-880-SparcIII-750MHz-CC-5.3 v2.17 -fast (sun4u) lt=9:50 16 threads 2048s/40*168e6=0.30us 30,10 1 28:10 55:32 SunFire-880-SparcIII-750MHz-gcc-4.1 v2.25 -O3 -mcpu=ultrasparc3 -mtune= 64v9 lt=8:56 n2=9m50 4m22/10It 4 threads 30,10 4 9:12 25:51 SunFire-880-SparcIII-750MHz-gcc-4.1 v2.25 -O3 -mcpu=ultrasparc3 -mtune= 64v9 lt=3:13 n2=4m06 3m08/10It 4 threads 30,10 4 7:52 21:40 SunFire-880-SparcIII-750MHz-CC-5.3 v2.19 -fast (sun4u) lt=6:11 4 threads (55s/5It) vbuf=16M 30,10 4 7:24 26:45 SunFire-880-SparcIII-750MHz-CC-5.3 v2.17 -fast (sun4u) lt=4:11 4 threads 4*910s/40*168e6=0.54us 30,10 4 7:12 26:28 SunFire-880-SparcIII-750MHz-CC-5.3 v2.17 -fast -O4 (sun4u) lt=4:05 4 threads 4*911s/40*168e6=0.54us 30,10 8 3:44 16:58 SunFire-880-SparcIII-750MHz-CC-5.3 v2.17 -fast (sun4u) lt=4:23 16 threads 8*532s/40*168e6=0.63us 30,10 1 13:42 25:56 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O3 -mcpu=ultrasparc3 4x4 (64bit) v2.25+ lt=4m26 n2=4m53 110s/10It (4DualCore) 32GB 30,10 1 9:04 20:26 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=4m50 n2=5m20 81s/10It (4DualCore) 30,10 1 9:01 19:30 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra3 -xarch=v9 (64bit) v2.25+ lt=4m37 n2=5m06 80s/10It (4DualCore) 30,10 2 5:26 13:49 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=3m16 n2=3m46 69s/10It (4DualCore) 30,10 4 3:07 8:16 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=1m49 n2=2m21 42s/10It (4DualCore) 30,10 8 1:46 7:43 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=2m55 n2=3m59 29s/10It (4DualCore) 30,10 2*8 1:23 5:05 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=1m34 n2=2m04 i40-n2-SH=98s/40It=245s/100It 30,10 2*8 2:00 5:39 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O3 -mcpu=ultrasparc3 (64bit) v2.25+ lt=1m29 n2=1m55 26s/10It (4DualCore) 32GB 30,10 2*8 2:04 5:40 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O2 -mcpu=ultrasparc3 (64bit) v2.25+ lt=1m25 n2=1m53 26s/10It (4DualCore) 32GB 30,10 1 19:00 48:14 GS160-Alpha-731MHz-cxx-6.3 v2.17 -fast -g3 -pg (42% geth_block, 27% b_smallest, 16% ifsmallest3) 30,10 1 21:12 50:37 GS160-Alpha-731MHz-cxx-6.3 v2.17 -fast 30,10 1 19:36 59:44 GS160-Alpha-731MHz-cxx-6.3 v2.17 -fast 16 threads 30,10 2 12:15 36:16 GS160-Alpha-731MHz-cxx-6.3 v2.17 -fast 16 threads 30,10 16 3:50 18:23 GS160-Alpha-731MHz-cxx-6.3 v2.15 ( 64 threads) 30,10 16 3:33 15:19 GS160-Alpha-731MHz-cxx-6.3 v2.15 (128 threads) simulates async read 30,10 1 21:20 43:55 GS160-Alpha-731MHz-cxx-6.3 v2.18 -fast lt=06:50 4m/10It 30,10 16 5:35 12:41 GS160-Alpha-731MHz-cxx-6.3 v2.18 -fast lt=02:51 1m/10It (640%CPU) 30,10 1 12:55 23:15 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=04:33 1m26s/10It = 10*840MB/1m26s=98MB/s 10*hnz/86s/1=20e6eps/cpu 50ns (max.80ns) 30,10 8 2:19 5:59 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=02:11 22s/10It (14%user+5%sys+81%idle (0%dsk) von 32CPUs) 10*hnz/22s/8=10e6eps/cpu 30,10 16 1:38 4:11 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=01:47 12s/10It 30,10 32 1:46 3:48 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=01:25 9s/10It 30,10 1 41:50 95:44 O2100-IP27-250MHz-CC-7.30 v2.17 -64 -Ofast -IPA 30,10 2 26:52 74:28 O2100-IP27-250MHz-CC-7.30 v2.17 -64 -Ofast -IPA (HBLen=1024 about same) 30,10 8 16:50 73:51 O2100-IP27-250MHz-CC-7.30 v2.17 -64 -Ofast -IPA 30,10 4 19:08 59:29 O2100-IP27-250MHz-CC-7.30 v2.18 -64 -Ofast -IPA 4x4 hnz+15% lt=00:13:00 -------- -------------------- 28,12 1 10:40:39 20:14:07 MIPS--IP25-194MHz-CC-7.21 v2.18 -64 -Ofast -IPA 1x1 lt=2h51m 50m/5It (dd_301720*20k=354s dd*5=30m /tmp1 cat=6GB/352s=17MB/s) 28,12 2 6:04:55 16:03:42 MIPS--IP25-194MHz-CC-7.21 v2.18 -64 -Ofast -IPA 2x2 lt=3h00m 52m/5It (ToDo: check time-diffs It0..It20?) 28,12 4 3:14:22 12:28:31 MIPS--IP25-194MHz-CC-7.30 v2.19 -64 -Ofast -IPA 4x4 lt=1h25m (59m)/5It 28,12 1 5h 10h GS160-Alpha-731MHz-cxx-6.3 v2.15 28,12 16 57:39 5:29:57 GS160-Alpha-731MHz-cxx-6.3 v2.15 (16 threads) 28,12 16 59:22 2:51:54 GS160-Alpha-731MHz-cxx-6.3 v2.15 (128 threads) . 28,12 1 3:03:00 10:04:03 GS160-Alpha-731MHz-cxx-6.3 v2.17pre -fast 28,12 3 1:13:27 5:45:12 GS160-Alpha-731MHz-cxx-6.3 v2.17 -fast -pthread 16 28,12 4 1:49:31 4:29:09 GS160-Alpha-731MHz-cxx-6.3 v2.18 -fast lt=25m home 10It/32..77m 7.5GB/635s=12MB/s(392s,254s,81s) tmp3=160s,40s,33s tmp3_parallel=166s,138s 28,12 8 52:57 2:17:00 GS160-Alpha-731MHz-cxx-6.5 v2.19 -fast lt=24m 13m30s/10It 28,12 1 2:00:56 4:08:31 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=53:23 17m17s/10It = 10*6GB/17m17s=58MB/s (3GB_local+3GB_far) 12e6eps/cpu 28,12 2 1:12:02 2:18:26 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=20:39 11m08s/10It = 10*6GB/11m08s=90MB/s 9e6eps/cpu 28,12 4 40:36 1:21:40 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=16:06 6m13s/10It 28,12 8 23:20 50:20 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=13:08 3m26s/10It 28,12 8 21:35 53:10 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=13:13 (2m04s..4m41s)/10It HBlen=409600 10*6GB/2m=492MB/s hnz*10/2m/8=10e6eps/cpu 28,12 16 14:01 32:17 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=10:46 1m51s/10It 28,12 32 13:09 27:50 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=08:37 1m29s/10It 28,12 32 15:41 30:57 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=08:42 1m24s/10It 70%user+7%sys+23%idle(0%io) 1user 4e6eps/cpu 28,12 1 3:19:39 7:02:48 SunFire-880-SparcIII-750MHz-CC-5.3 v2.18 -fast (sun4u) lt=1h05m 1 threads (19m40s/5It) 28,12 2 1:48:28 4:29:24 SunFire-880-SparcIII-750MHz-CC-5.3 v2.18 -fast (sun4u) lt=47:17 2 threads (14m08s/5It) 28,12 4 58:41 2:42:08 SunFire-880-SparcIII-750MHz-CC-5.3 v2.18 -fast (sun4u) lt=36:36 4 threads (8m/5It, 4cat=6GB/0.5s) (FLOAT: same, sh=59:16 i40=2:37:09 lt=38:48 7m17s/5It) 28,12 8 35:59 1:47:38 SunFire-880-SparcIII-750MHz-CC-5.3 v2.18 -fast (sun4u) lt=29:39 8 threads (5m/5It) 28,12 1 91:19 198:24 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O3 -mcpu=ultrasparc3 (64bit) v2.25+ lt=27m18 n2=29m52 9m17s/10It (4DualCore) 32GB 28,12 1 63:21 150:33 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=30m02 n2=32m57 13m32s/10It (4DualCore) 32GB 28,12 2 38:31 107:45 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=20m02 n2=22m58 11m32s/10It (4DualCore) 28,12 4 22:09 62:11 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=10m52 n2=13m58 6m30s/10It (4DualCore) 28,12 8 12:17 42:57 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=10m05 n2=13m25 4m15s/10It (4DualCore) 8threads 28,12 2*8 10:14 39:00 SunFire-V490-Sparc4+-1500MHz-CC-5.3 -fast -xtarget=ultra -xarch=v9 (64bit) v2.25+ lt=10m06 n2=13m02 3m55s/10It (4DualCore) 16threads 28,12 2*8 14:31 43:09 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O3 -mcpu=ultrasparc3 (64bit) v2.25+ lt=9m26 n2=12m00 4m08s/10It (4DualCore) 32GB 28,12 2*8 14:44 43:48 SunFire-V490-Sparc4+-1500MHz-gcc4.1.1 -O2 -mcpu=ultrasparc3 (64bit) v2.25+ lt=9m13 n2=12m00 4m15s/10It (4DualCore) 32GB 28,12 1 54:19 1:53:43 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=19m (9m36s)/10It hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 28,12 2 32:42 1:20:55 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=13m (8m19s)/10It hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 28,12 4 19:40 1:07:17 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=7m (9m38s)/10It hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) memory distributed badly? 28,12 1 71:37 2:14:45 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=25m52 n2=27:42 (8m36s/10It) Novel10-32bit 32G-RAM dsk=6MB/s 28,12 2 44:31 1:31:31 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=16m25 n2=18:18 (6m59s/10It) Novel10-32bit 32G-RAM dsk=6MB/s 28,12 4 23:30 51:54 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=10m06 n2=12:00 (4m09s/10It) Novel10-32bit 32G-RAM dsk=6MB/s # Novel10-32bit: mount -t tmpfs -o size=30g /tmp1 /tmp1 # w=591MB/s 28,12 4 20:17 85:03 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=9m05 n2=10:47 (13m33s/10It) knoppix-5.0-32bit 4of32G-RAM dsk=60MB/s 28,12 8 11:30 91:56 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=8m53 n2=10:35 (16m54s/10It) knoppix-5.0-32bit 4of32G-RAM dsk=60MB/s 28,12 2*8 9:39 104:06 4xDualOpteron885-2600MHz-gcc-4.0.4 32bit lt=8m56 n2=10:38 (20m29s/10It) knoppix-5.0-32bit 4of32G-RAM dsk=60MB/s 28,12 1 47:41 108:12 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=30m n2=32:15 (7m03s/10It) kanotix2005-04-64bit 16G-RAM tmpfs 28,12 2 30:19 80:48 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=22m n2=24:03 (6m36s/10It) kanotix2005-04-64bit 16G-RAM tmpfs 28,12 4 16:29 45:49 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=16m55? n2=13:27 (3m30s/10It) kanotix2005-04-64bit 16G-RAM tmpfs 28,12 8 9:01 28:13 4xDualOpteron885-2600MHz-gcc-4.0.3 64bit lt=8m29 n2=10:18 (2m13s/10It) kanotix2005-04-64bit 16G-RAM tmpfs 28,12 1 1:04:36 2:04:00 Xeon-3GHz-12GB-v2.24-gcc-4.1 64bit 4x4 lt=22m (8m36s)/10It model4 stepping10 n2=24m44 xen 28,12 2 37:42 1:28:24 Xeon-3GHz-12GB-v2.24-gcc-4.1 64bit 2x2 lt=16m (7m28s)/10It model4 stepping10 n2=18m18 xen 28,12 4 29:46 1:17:56 Xeon-3GHz-12GB-v2.24-gcc-4.1 64bit 4x4 lt=11m (8m51s)/10It model4 stepping10 n2=13m15 xen 28,12 1 1:13:28 2:42:16 Xeon-3GHz- 2GB-v2.25-gcc-4.0.2 32bit 4x4 lt=29m (13m46s)/10It model4 stepping3 n2=31m34 28,12 1 1:06:07 2:30:48 Xeon-3GHz- 2GB-v2.24-gcc-4.1.1 32bit 4x4 lt=28m (13m33s)/10It model4 stepping3 n2=30m16 28,12 8 13:42 49:10 Xeon-2660MHz-2M/8GB-v2.25-gcc-4.1.1 amd?64bit model6 stepping4 lt=8m43 n2=11m30 7m13/10It 2*DualCore*2HT=8vCPUs bellamy san=w142MB/s,r187MB/s 28,12 2*8 12:40 48:23 Xeon-2660MHz-2M/8GB-v2.25-gcc-4.1.1 amd?64bit model6 stepping4 lt=8m08 n2=10m54 6m01/10It 2*DualCore*2HT=8vCPUs bellamy san=w142MB/s,r187MB/s -------- -------------------- 1.4GB + 14GB 27,13 4 141:06 384:27 SunFire-880-SparcIII-750MHz-CC-5.3 v2.19 -fast -xtarget=ultra -xarch=v9 -g -xipo -xO5 lt=73:15 (21m14s/5It) 27,13 8 57:59 138:59 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=28m (6m38s)/5It HBLen=409600 27,13 16 46:03 103:21 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=25:44 (3m50s..3m57s)/5It mfs-disk + vbuf=16MB + sah's 27,13 32 29:18 61:25 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=18:03 (1m43s..1h38m)/5It (2stripe-Platte=150MB/s) 60%user+5%sys+35%idle(0%disk) 1user -------- -------------------- 2.6GB + 28GB 26,14 16 45:51 1:45:48 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=27m07 (4m00s...4m12s)/5It mfs-disk vbuf=16M + spike (optimization after linking) 26,14 16 91:49 3:31:01 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=48m34 (7m57s..10m01s)/5It mfs-disk vbuf=16M 26,14 1 4:23:00 13:58:37 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=76m (123m)/10It 16blocks hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 26,14 2 2:49:53 10:00:26 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=50m ( 91m)/10It 2blocks hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) io.r=50MB/s 26,14 4 1:32:16 6:53:23 2CoreOpteron-2194MHz-gcc-3.4 v2.23 -O2 lt=26m39 ( 72m)/10It 4blocks hxy_size=163840/32768=5 mem=16GB 2*DualCore (loki.nat) 26,14 8 32:06 1:42:33 4xDualOpteron885-2600MHz-gcc-4.1 64bit lt=18m32 n2=25:18 (10m24s/10It) SLES10-64bit 32G-RAM 26,14 1 4:56:57 11:36:23 Xeon-3GHz-12GB-v2.24-gcc-4.1 64bit 4x4 lt=1h28m ( 75m)/10It model4 stepping10 26,14 2 3:03:22 8:58:02 Xeon-3GHz-12GB-v2.24-gcc-4.1 64bit 2x2 lt=1h06m ( 70m)/10It model4 stepping10 26,14 128 11:10 72:00 Tina-Cluster 128*DualXeon-3GHz 2*100Mbit-eth v2.32 lt=9m ( 13m)/10It flt Feb08 -------- -------------------- 25,15 8 3:03:41 15:54:51 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=1h24m (1h18m..1h26m)/5It HBLen=409600 24,16 8 4:58:56 25:21:48 GS1280-Alpha-1150MHz-cxx-6.5 v2.19 -fast lt=2h08m (2h16m)/5It HBLen=409600 24,16 8 8:31:10 31:49:42 Altix330IA64-1500MHz-gcc-3.3 v2.23 -O2 lt=3h14m (4h55m)/10It hxy_size 163840/32768=5 23,17 4 17:19:51 51:02:31 ES45-Alpha-1GHz-CC-6.5 -fast -lz v2.18 lt=04:11:14 latency=29h30m/40*63GB=42ns cat=2229s(28MB/s) zcat=5906s(11MB/s)
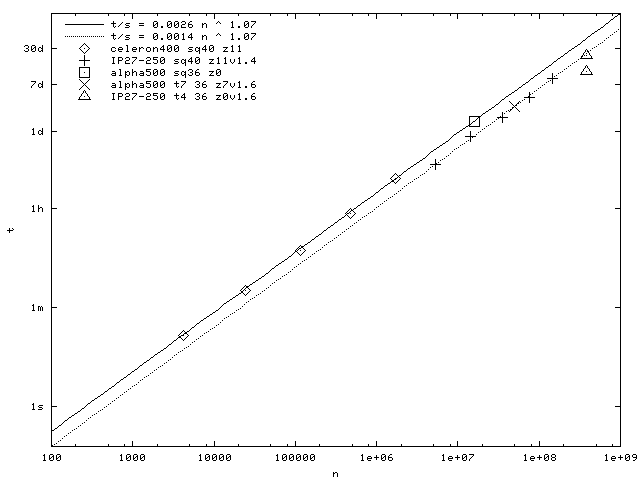
Next figure shows the computing time for different older program versions and computers (I update it as soon as I can). The computing time depends nearly linearly from the matrix size n1 (time is proportional to n1^1.07, n1 is named n in the figure).
Memory usage depends from the matrix dimension n1. For the N=40 sample two double vectors and one 5-byte vector is stored in the memory, so we need n1*21 Bytes, where n1 is approximatly (N!/(nu!*nd!))/(4N). Disk usage is mainly the number of nonzero matrix elements hnz times 5 (disk size for tmp_l1.dat is 5*n1 and is not included here). The number of nonzero matrix elements hnz depends from n1 by hnz=11.5(10)*n1^1.064(4), which was found empirically. Here are some examples:
# hnz/n1=10.4*n1**0.069 (old) per gnuplot fit (should be f(x)=1..x for small x) # max. hnz/n1 using AddSS nud n1 memory hnz/n1 disk (n1*21=memory, hnz*5=disk) -----+---------------+---------------------- 2,38 11 232 4.1 225 160sym E= 12.10565871 AddSS=+18 4,36 632 13kB 15.8 60kB 160sym E= 4.69533136 AddSS=+16 6,34 24e3 432kB 21.92 2.6MB 160sym E= -2.11313499 8,32 482e3 11MB 27.0 66MB 160sym E= -8.22686823 SMag= 0.14939304 10,30 5.3e6 113MB 31.74 840MB 160sym E=-13.57780124 n1<2^23 * 12,28 35e6 735MB 35.38 6GB 160sym E=-18.11159089 n1<2^27 13,27 75e6 1.4GB 37.3 14GB 160sym n1=75214468 14,26 145e6 2.6GB 38.17 28GB 160sym E=-21.77715233 ZMag= 0.02928151 n1=145068828 15,25 251e6 5.3GB 39.4 50GB 160sym 16,24 393e6 8.3GB 40.2 79GB 160sym E=-24.52538640 17,23 555e6 11.7GB 41.4 115GB 18,22 708e6 14.9GB ... ... n1<2^30 20,20 431e6 7.8GB 41.8 90GB 2*160sym E=-27.09485025 -----+---------------+---------------------- 6,34 3.8e6 80MB 22.1 422MB 1sym E= -2.11313499 8,32 77e6 1.6GB 27.3 10GB 1sym E= -8.22686823 Performance prediction: ToDo: min,mean,max GS1280-i100-time-estimation for 28,12: (measured: ca.50min/100=30s) get_vector1: n1*(dbl/rspeed+double/wspeed) 35e6*16/2e9/s=0.28s get_matrix: hnz*Hsize/rspeed 1.2e9*5/2e9/s=3s (or DSK!) get_vector2: hnz*(double/rspeed...latency) 1.2e9*(8/2e9..82ns)=5s..98s idx+mult+add: hnz*3clocks 1.2e9*3/1250e6=3s load_program_instructions: cached (small loop) # latency=82..250e-9s clock=1/1250MHz speed=2e9B/s (estimations) # latency L1=1clk,L2=12clk=10.4ns,mem=102.5clks clock=0.8e-9s # 18.4GB/s max=767MHz*8*2=12.3GB/s,remote=6.2GB/s # 1.75MB 8channels? -> 8*latency-overlap? # random-hitrate 1.75MB/735MB=0.2% ToDo: measure hitrate # # mpi_blocksize=1..hnz/n1/nodes...hnz/nodes depends on code version # max_mpi_overhead=(hnz/BW+pingpong*hnz/blocksize)*%hnz_inter_node # 28+12sample: 6GB/.25GB/s+10e-6s*35e6=24s+350s=6.2min*13% ca. +80%i100
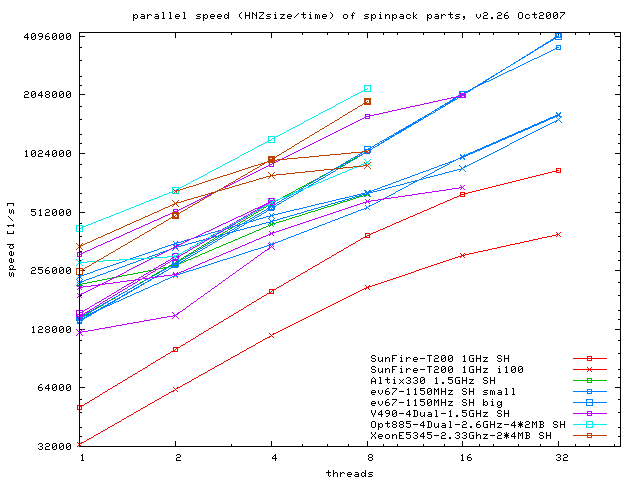 CPU-scaling for spinpack v2.26 (Oct2007)
CPU-scaling for spinpack v2.26 (Oct2007)
The T200 has 8 Cores with 4 Threads per Core (CMT). SH is the matrix generation (integer-OPs), i100 are 100 Lanczos-iterations (FLOPs and memory transfers). Created by the gnuplot file speed.gpl.
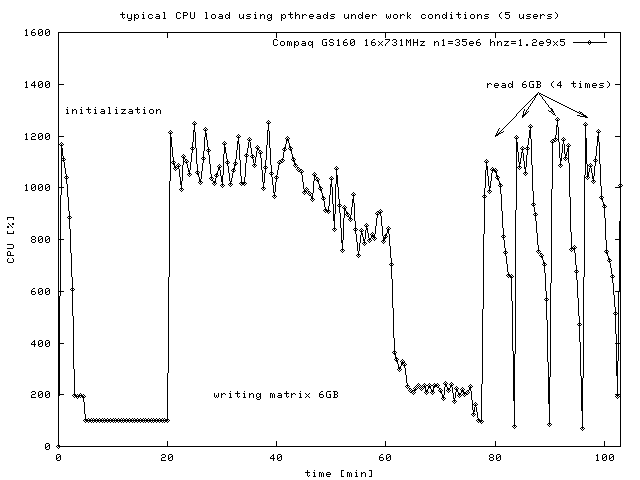
A typical cpu load for a N=40 site system looks like this:
Data are generated using the following tiny script:
#!/bin/sh
while ps -o pid,pcpu,time,etime,cpu,user,args -p 115877;\
do sleep 30; done | grep -v CPU
115877 is the PID of the process. You have to replace it.
Alternatively you can activate a script activated by daten.i (edit it).
The machine was used by 5 users, therefore peak load is only
about 12CPUs. 735MB memory and 6GB diskspace (or cache) were used.
You can see the initialization process (20min),
the matrix generation (57min) and the first 4 iterations (4x8min).
The matrix generation is most dependend from CPU power.
The iteration time mainly depends from the disk speed
(try: time cat exe/tmp/ht* >/dev/null) and the
speed of random memory access. For example a GS1280-1GHz needs a
bandwith to the disk of 60MB/s per CPU to avoid a bottle neck.
Reading 5GB in 8min means a sequential data rate of 12MB/s which
is no problem for disks or memory cache. Reading randomly a 280MB
vector in 8min means 600kB/s and should also be no problem for the
machine.
You can improve
disk speed using striped disks or files (AdvFS) and putting every
H-block on another disk. The maximum number
of threads was limited to 16, but this can be changed (see src/config.h).
During iterations the multi-processor scaling is so bad on most machines -- why? I guess, this is because of random read access to the vector a (see picture below). I thought a shared memory computer should not have such problems with scaling here, but probably I am wrong. In future I try to solve the problem.
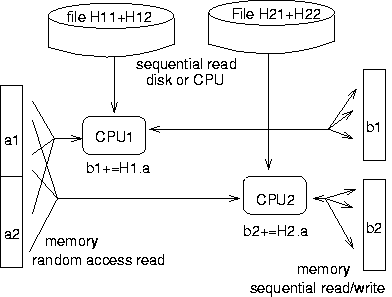
Figure shows dataflow during iterations for 2 CPUs.
Version 2.24 was very slow in calculating the expectation value of <SiSj>. A gprof analysis was showing, that most time was spend for finding the index of an configuration in the configuration table (function b2i of hilbert.c). This was the reason to have a closer look to the speed of memory access. I wrote memspeed.c which was simply read a big number of integers at different steps. Reading integers one after another (sequential read) gives the best results of the order of 1-2GB/s. But worst case where integers are read at distance of about 16kB gives performance of about 10-40MB/s which is a factor of 100 smaller. This is a random access to the RAM. The OpSiSj-function does arround n1*(ln2(n1)+1) such accesses to memory for every SiSj value calculation. I think it should be possible to reduce the randomness of index calculation by using ising energy of each config to divide the configs in blocks. (Sep2006)