unintended power-off-problem
This page is for detailed description of the power-off-problem
explored at our HPC-cluster Sofja.
If you are a cluster administrator and
have similar problems, please contact me to share
our experiences. Problem seems to be fixed
at Mar23 by a special BMC-FW-update. 14 days with no failures.
short hardware description
We have installed a new HPC-system with about 300 compute nodes
(8 racks). Boards are D50TNP1SB (4 boards per 2 HE chassis by Intel).
Each has 2 sockets with "Intel(R) Xeon(R) Gold 6326 CPU @ 2.90GHz" CPU,
16 16GB-DDR4-ECC-DIMMS (3200 MT/s) by Samsung, and
Infiniband controller (Mellanox Technologies MT28908 Family [ConnectX-6],
100Gb/s).

short problem description
Nodes switch off unintended and cannot be switched on, neither remotely nor
by the power button. Nodes must be pulled to disconnect from power
and plugged back.
At September 2022 after about 10 months operation
this happens about once a day.
Here is a sample System Error Log (SEL):
29 | 09/14/2022 | 12:59:46 | Power Unit Pwr Unit Status | Power off/down | Asserted
And if tried to switch on remotely (power led is still green):
2d | 09/15/2022 | 14:08:16 | Power Unit Pwr Unit Status | Soft-power control failure | Asserted
2e | 09/15/2022 | 14:08:16 | Processor P2 D1 Status | Thermal Trip | Asserted
2f | 09/15/2022 | 14:08:17 | Processor P1 D1 Status | Thermal Trip | Asserted
And if power button pressed (power led is still green, ib-led is off):
52a | 10/07/2022 | 07:37:20 | Button Button | Power Button pressed | Asserted
52b | 10/07/2022 | 07:37:28 | Power Unit Pwr Unit Status | Failure detected | Asserted
52c | 10/07/2022 | 07:37:28 | Processor P2 D1 Status | Thermal Trip | Asserted
52d | 10/07/2022 | 07:37:29 | Processor P1 D1 Status | Thermal Trip | Asserte
Than power led is off, error lamp goes orange.
Because power LED still shows green light, whereas the node is off,
it is very likely the BMC or some HW is in a bad state.
A "bmc reset cold" does not recover the power-on function.
The SEL messages "Thermal Trip" (de: thermische Reise?)
appear since the August FW-update.
It looks like sensors are in a bad state too.
way to force the error
It is possible to force such errors by changing maximum
frequency of the CPUs for minimum about 130 nodes simultaneously by:
cpupower frequency-set --max 800000 # fmax=800MHz = Minimum Freq.
and after about 2 minutes
cpupower frequency-set --max 3500000 # fmax=3500MHz (or less)
Usually we sequentially do ssh to each node by a for-loop
and call the cpupower command to switch frequency down or up.
This takes about 2 minutes for all nodes.
After that we test for failed nodes, we count and show them.
With less than 130 nodes we have rarely seen failed nodes.
Our experience is, we get
one failing node for 4 racks (ca. 130 nodes) and 20-30 failing nodes
with 8 racks (ca. 280 nodes). That is the reason for assuming
power supplies (PSUs)
are involved as a (electrical) communication path between nodes
(we do not have a proof).
We do not do this test very often, because it takes time (footpath
and ensured doors) to get the nodes back to work and there is the risk
that nodes or power supplies may fail permanently.
At August 2022 we had 88 nodes (30%) unintended
powered off after 3 rounds testing.
As a consequence we tried to set moderate max frequencies, disabled turbo
modes and performance within the linux OS with no or low help.
update 2022-10: force-errors failed for unknown reason
update 2023-02: force errors works partly, depends from some
unknown state(!?), CPU freq-gov=performance needed (?), powercap works the
same way, faster than ssh via srun -Z -w ...
aging involved?
Without knowledge we did frequency changing first time
at November 2021. The System Error Logs (SEL) show that we had
two power off fails at that time.
At August 2022 as we repeated the frequency change we had 20-30
nodes turned out with unintended power off.
Also the unintended-power-off rate at normal operation has
clearly grown by time.
Also nodes with multiple power offs tend to fail completely.
Most of those nodes finaly still work,
but show CPU frequency below 200MHz permanently (15 nodes at Oct22).
The slow-down factor of applications is between 20 and 45.
Some others do not boot or boot sequency is interrupted by kernel crashs.
Update Nov22: low freq problem was fixable by ipmi raw command,
thanks to hpc.fau.de fellows
Update Feb23: setting power capping to 1W temporary reproduces the
low frequency behaviour (looks like system has detected overload,
linux shows maximum power capping as 652W = 3.5 * TDP, TDP=185W).
A slurm-health script was misconfigured from the beginning
to work allways and caused every minute a power spike at
low usage (or drop at high usage). Fixed in Feb23 to 5min at IDLE.
still no single node failure reproducer, even for nodes fail more often
external (electrical) disturbances?
External disturbances are unlikely.
Especially that we can force the error by changing the CPU
frequency range is a strong hint that we have an internal problem.
Feb23 we tried to put a rack to the online-UPS and further had
power offs on that rack.
manufacturer support?
Some of our failed boards are on the way to the manufacturer.
They will check the board components per x-ray. Also a fix must be
found when problem is located. That will take weeks or months.
Update: the outcome was "no shortcuts",
Jan23: all power supplies were replaced by newer revision,
without success.
Possibly the new revision is still to bad
(still bitflip and NA problems there).
Feb23: first time special firmware with debug function was applied.
Nodes power on automatically after off-failure.
Mar23: BMC-FW update, 14 days no failures,
power-off problem seems to be fixed (!)
error distribution
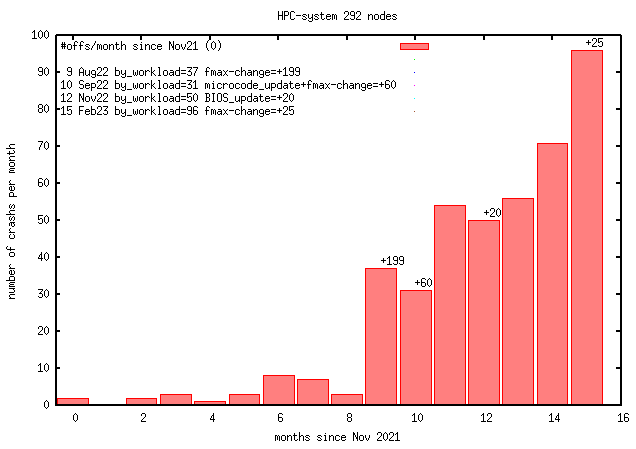
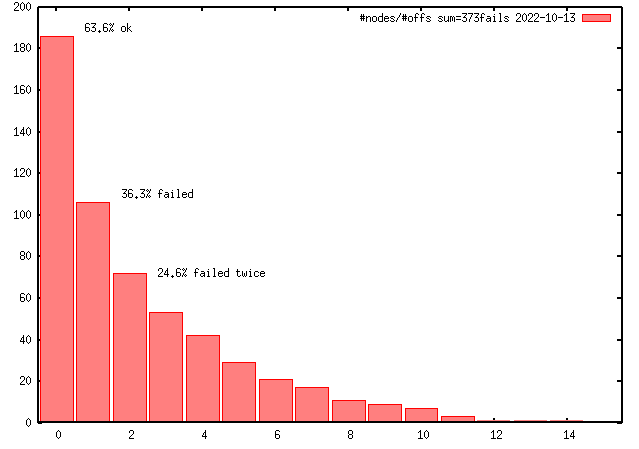
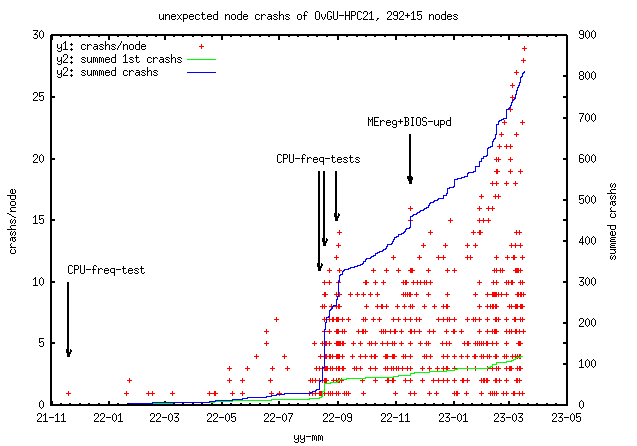
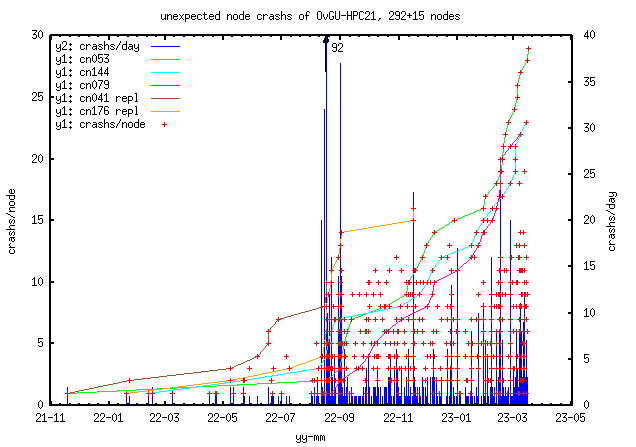
Last above figure shows crash details.
Bigger gaps between crashs can be explained by nodes stayed off (22-07
holiday), nodes send to the technical support for analysis or
nodes replaced. CPU-freq-test means setting all CPUs maximum frequency to a
low or the lowest value (800 MHz) and setting it back to a high
(highest 3500MHz) value. Since 2022-09 the scaling governour was set to
powersave, the default was performance.
With time nodes tends to crash in groups as part of a bigger slurm-job
or/and on the next jobs.
update 2023-02: looks like power transients are involved
(p.e. all cores starting loads), most power offs happen in
waves of failing nodes within minutes, partly during the next job starts
or houres later if left idle
update 2023-03: 14 days with no failures after BMC-FW-update (not shown)
energy flow


If the problem is power supply induced (150MHz is mostly on quads),
the error distribution must be by quad-nodes.
This would make the statistic even worse. 15 Quads (21%) are not affected.
57 Quads (79%) are affected.
emv-measurements
Thanks to the
Chair of Electromagnetic Compatibility
(EMV) we could do some more detailed measurements of our power network.
We recorded high time resolution voltage and current measurements
at rack 5 on events with high deviation from normal behavior.
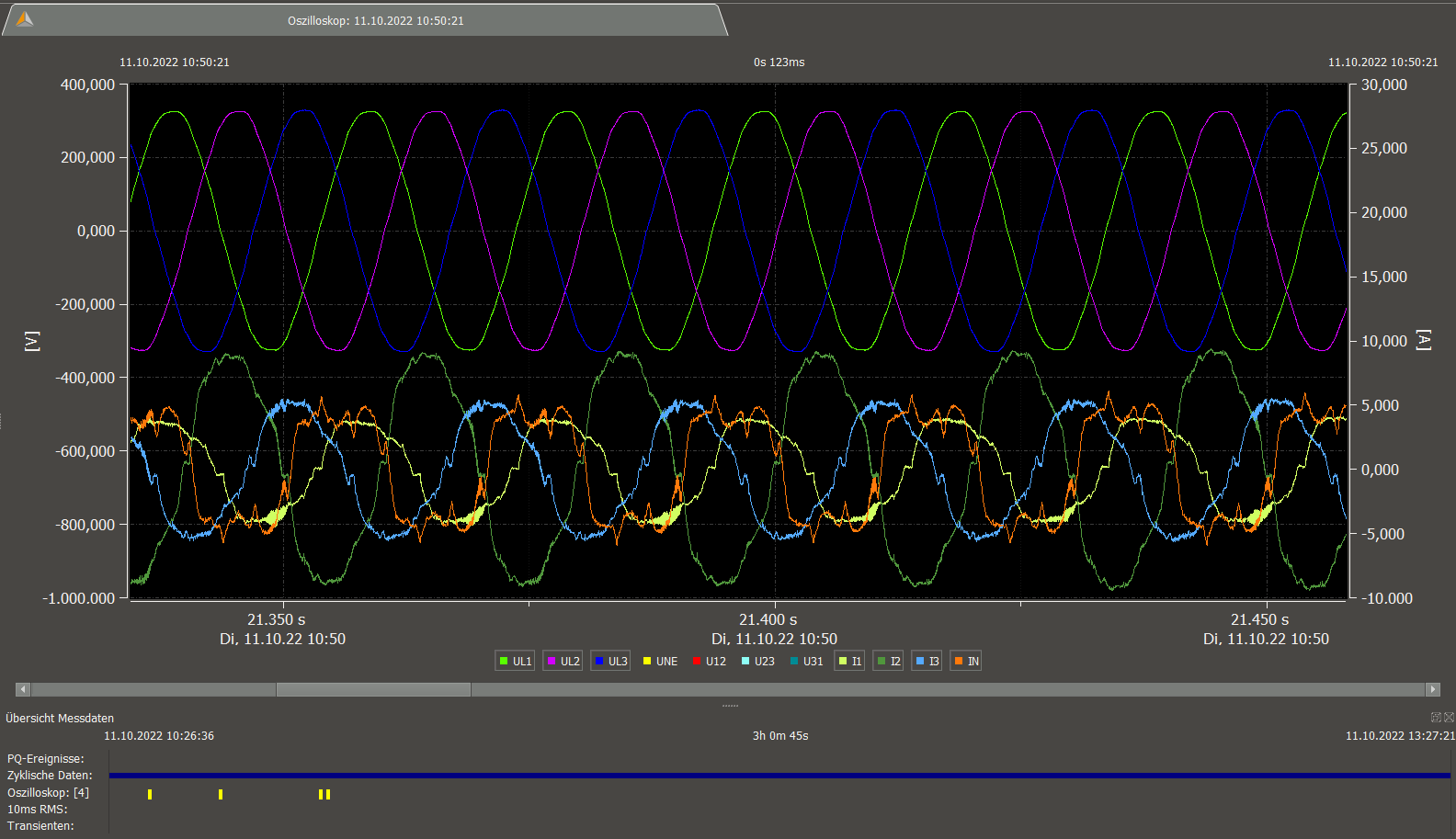
10kHz ripple at rack 5 PDU-B, this will very likely come from the
DC/DC-converters of the PSUs (usually the Power Factor Correction (PFC)
behind the rectifiers is designed as 400V stepup,
where 10kHz is in the common frequency range of DC-converters).
Normally passive LC-filters between the PFC and the 230V connector
should filter this out.
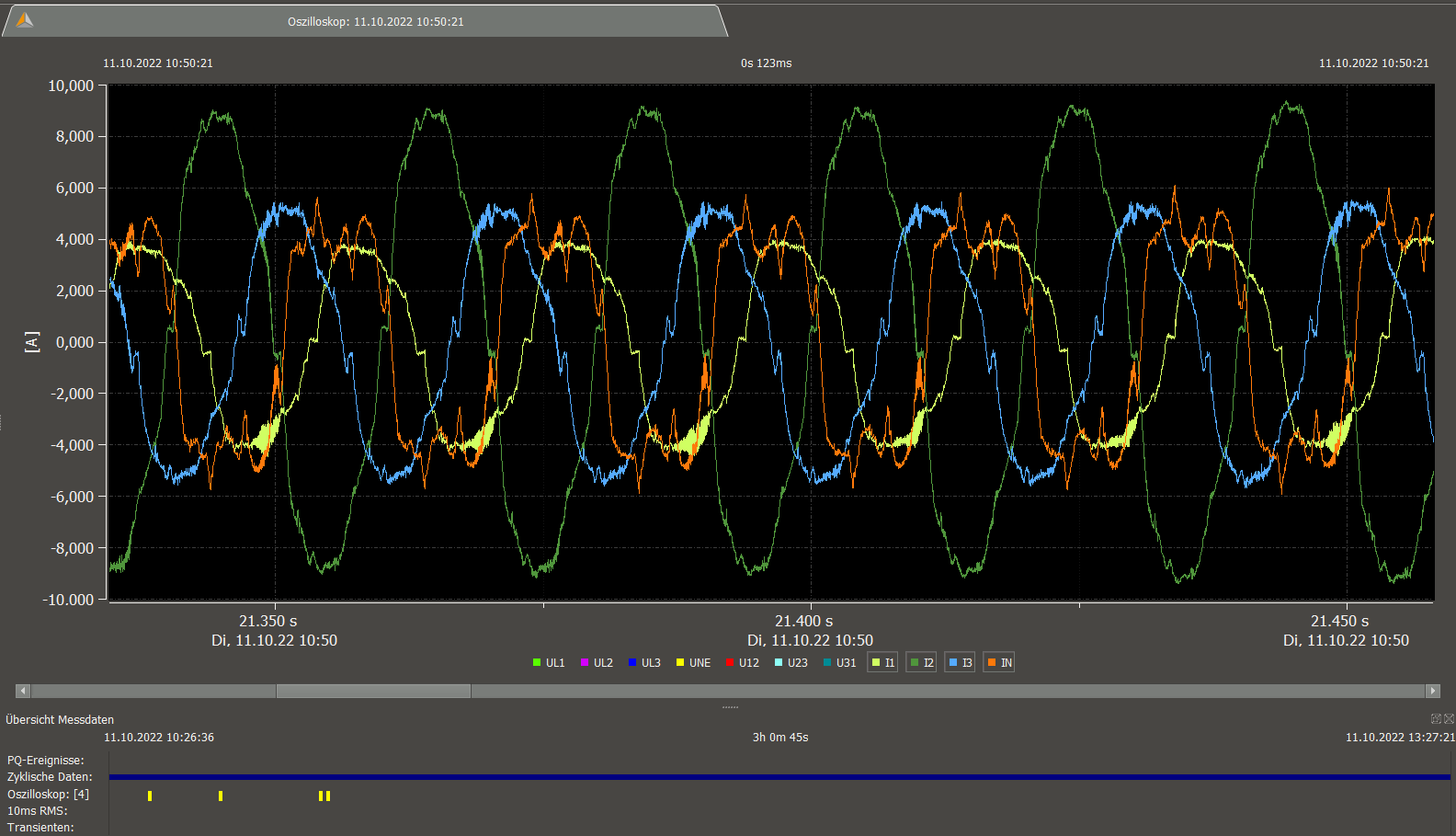
10kHz ripple at rack 5 PDU-B current
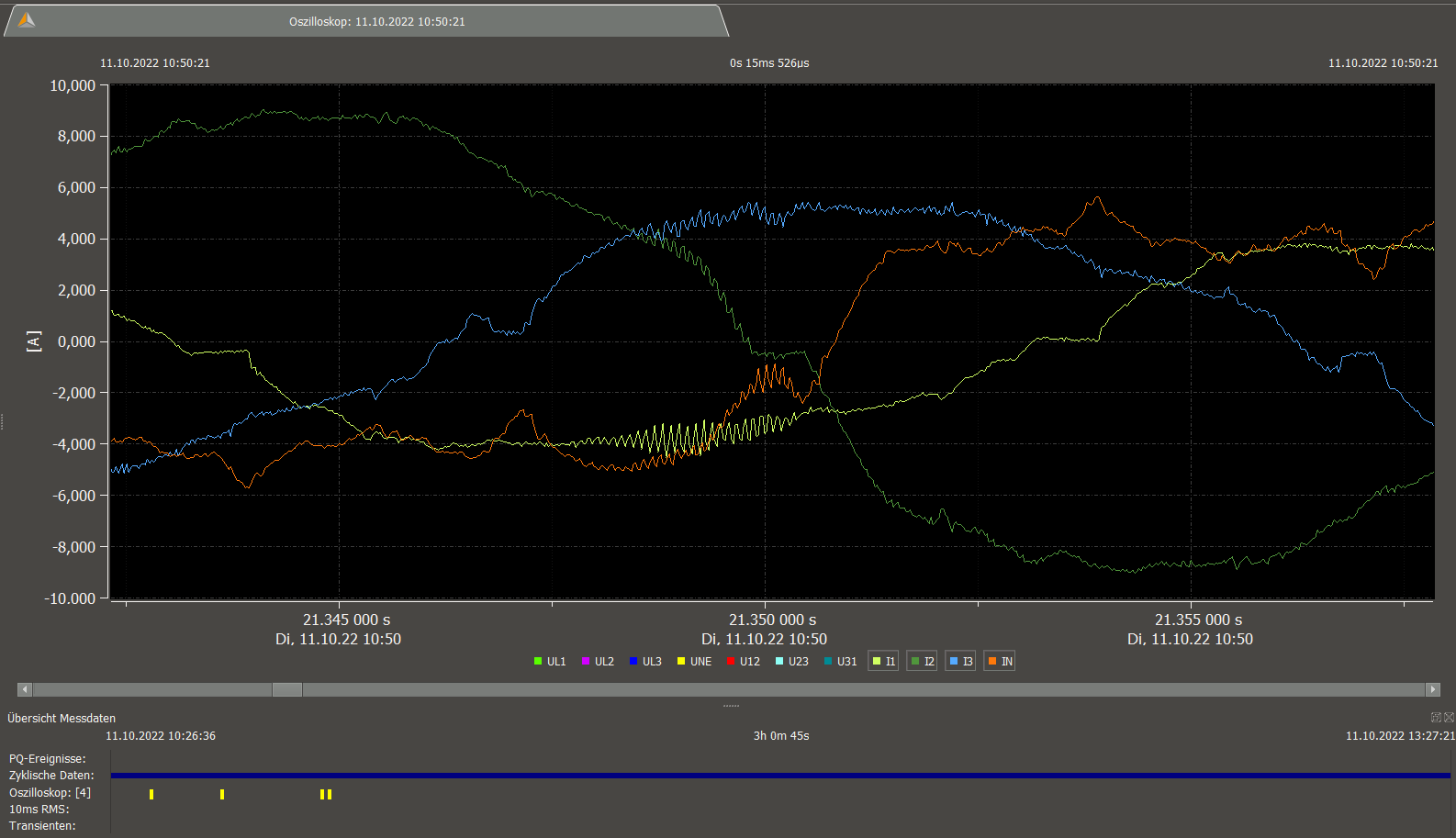
10kHz ripple at rack 5 PDU-B current detail
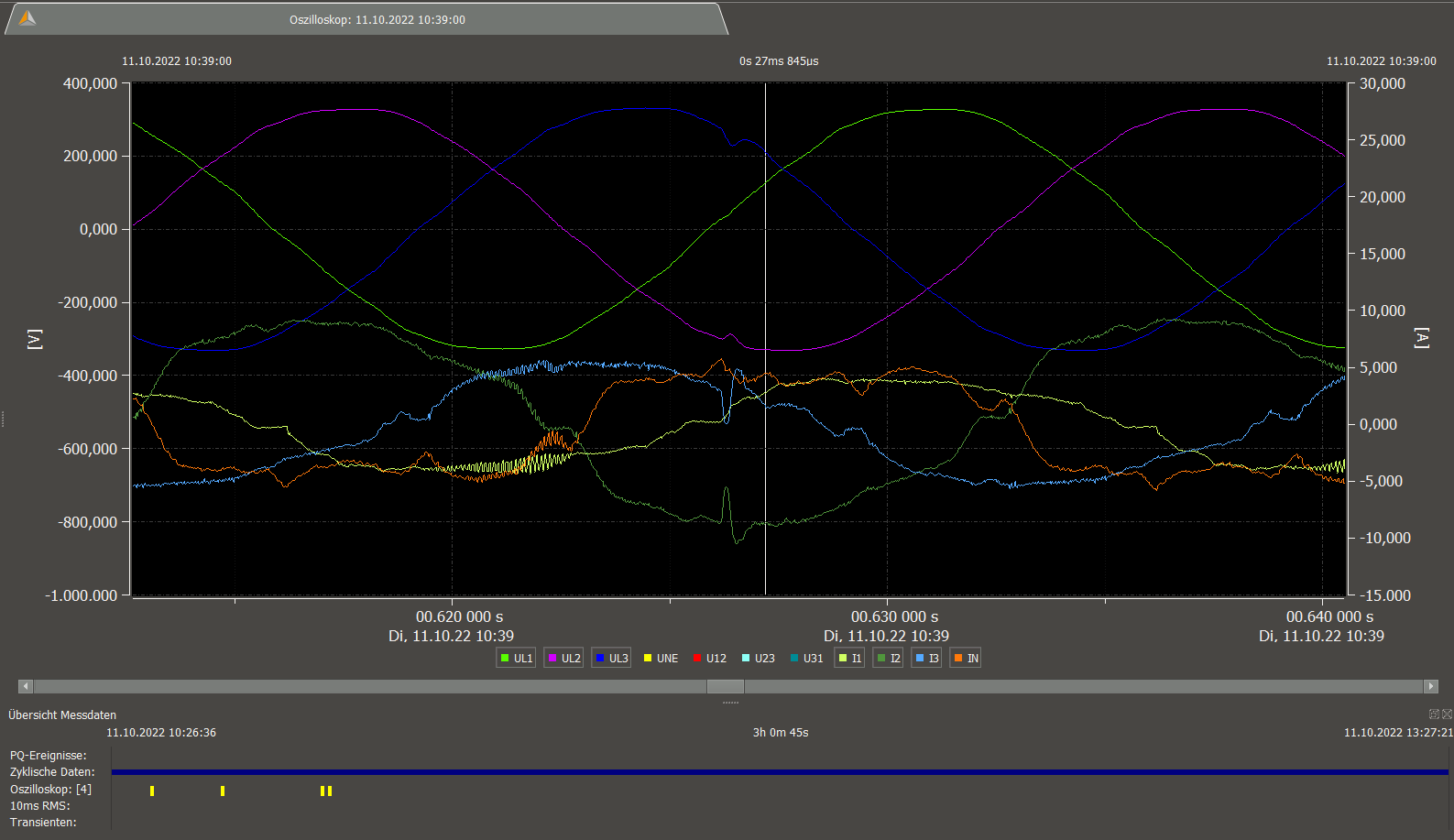
power drop at rack 5 PDU-B I-L2, I-L3 synchronized
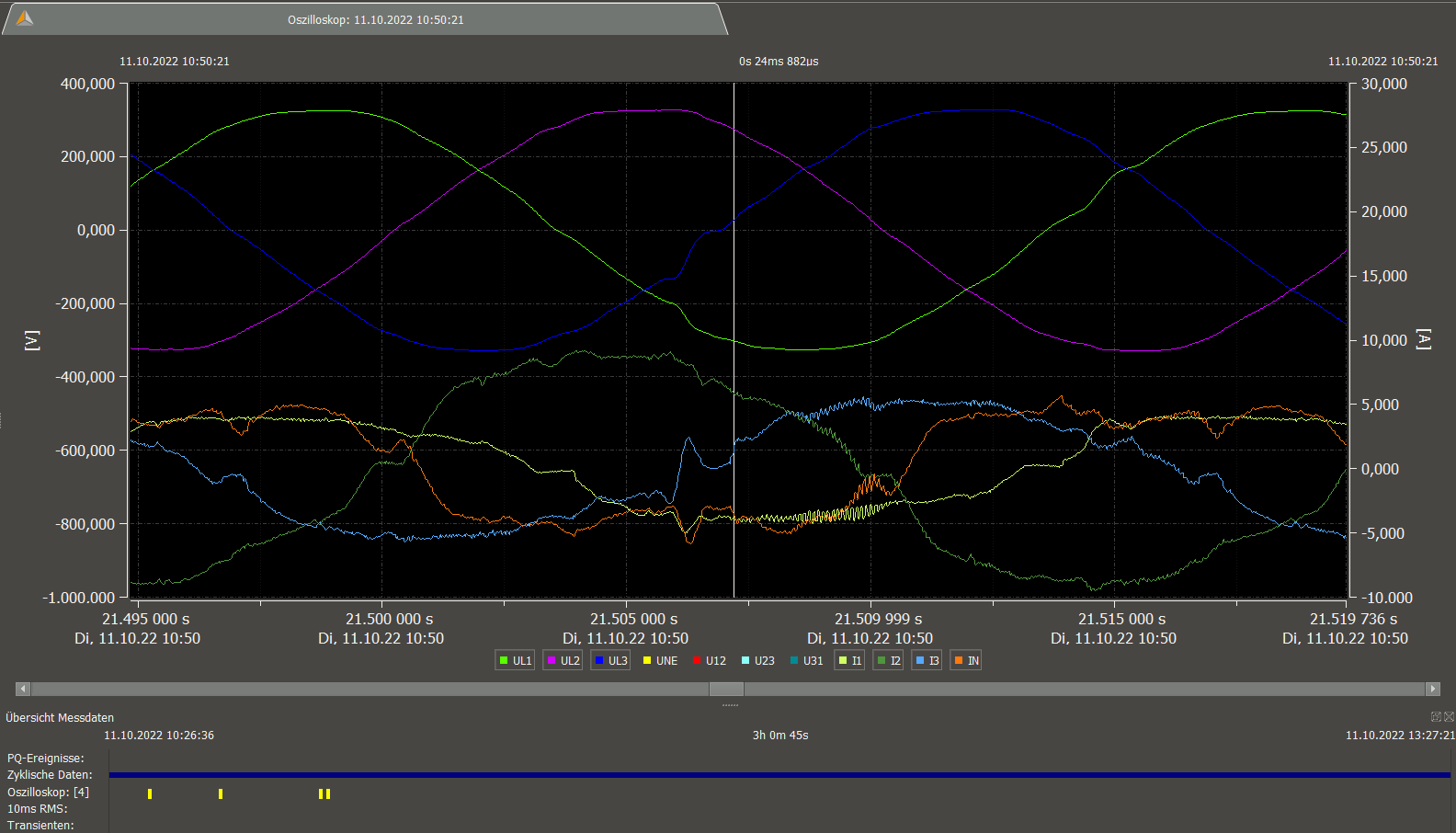
power I1-peak + I3-drop at rack 5 PDU-B (voltage induced?)
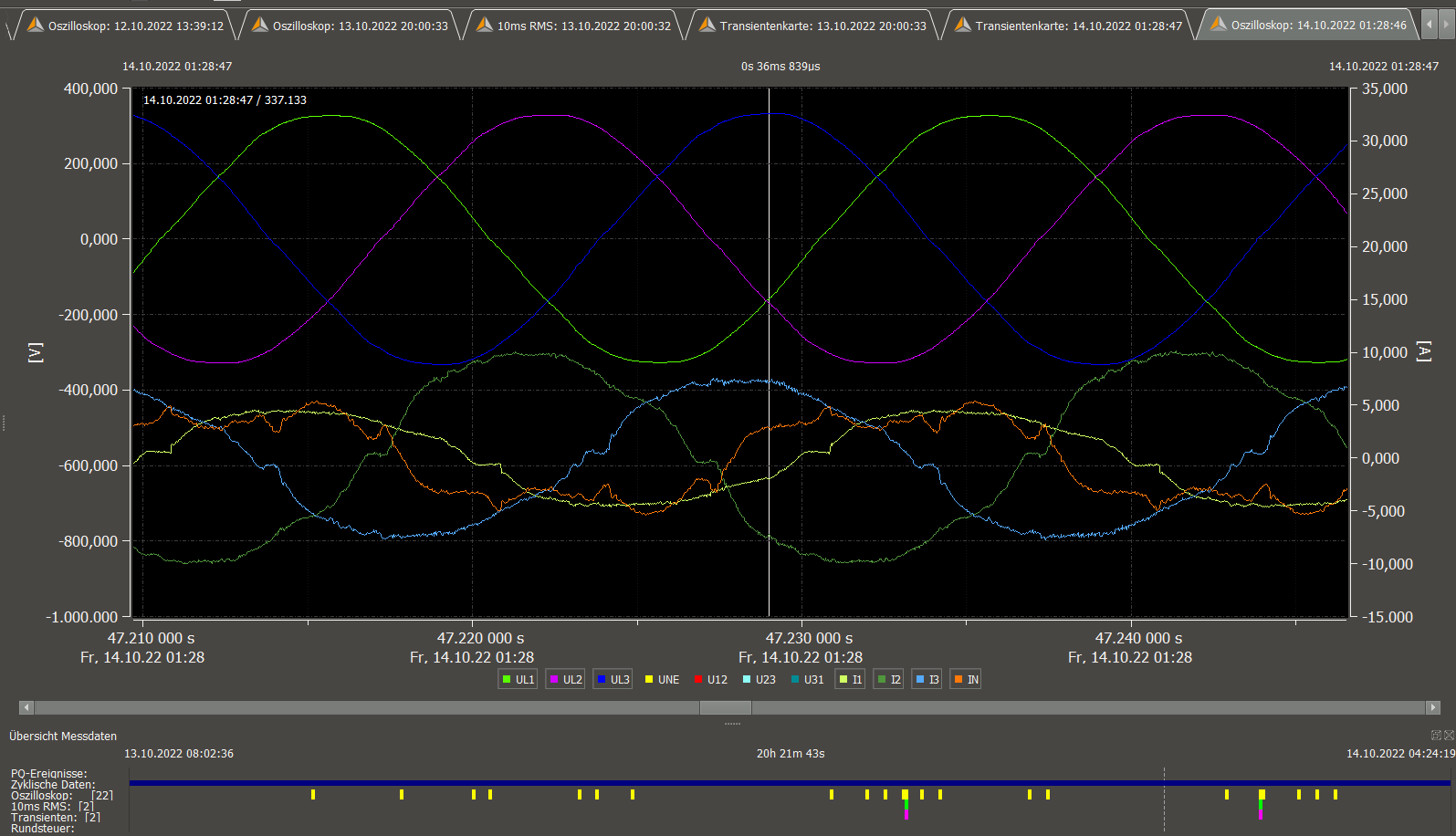
voltage UL2 spike ca. 1us at 47.235099s (not resolved)
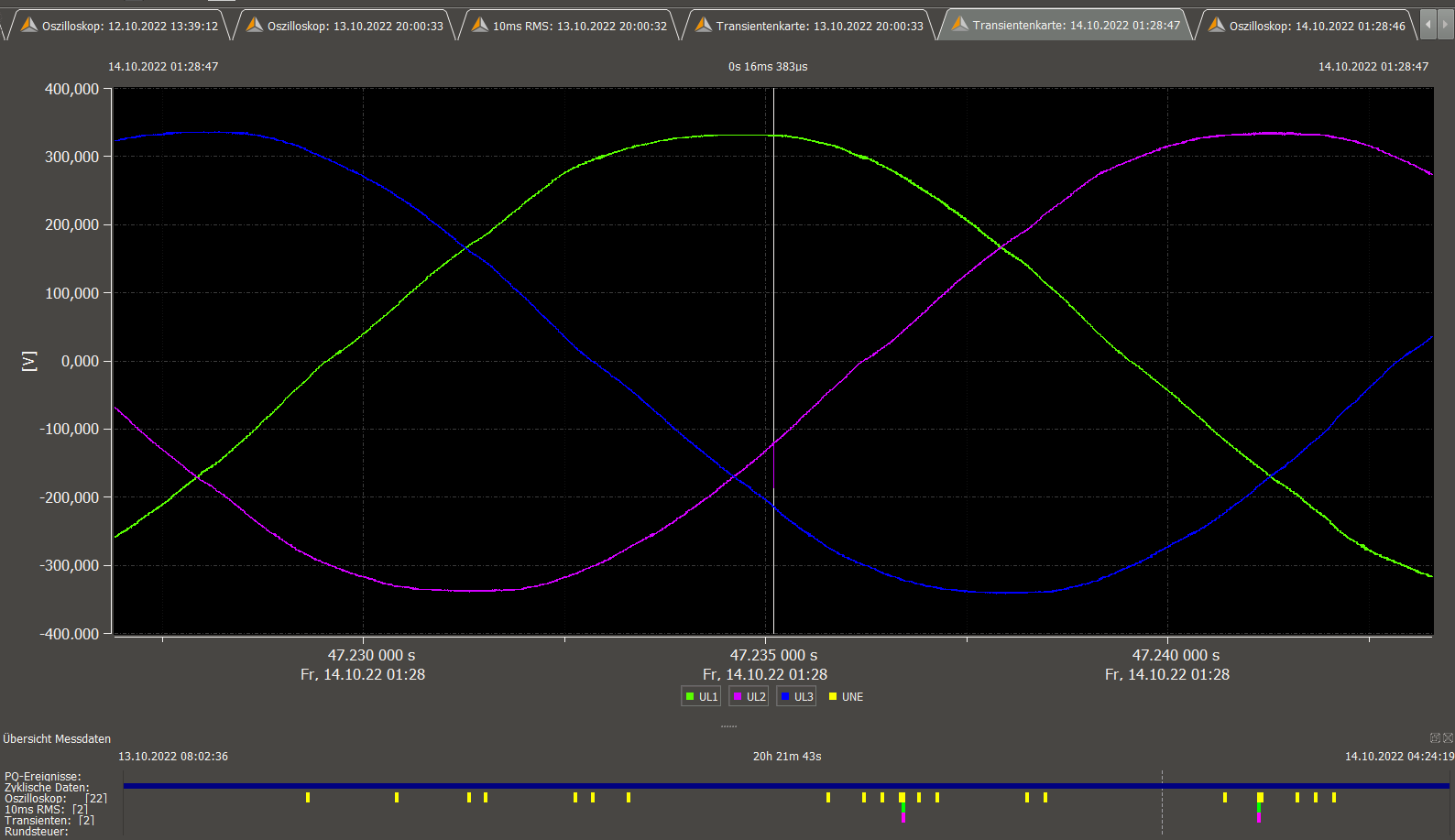
voltage UL2 spike ca. 1us at 47.235099s (not enough resolved)
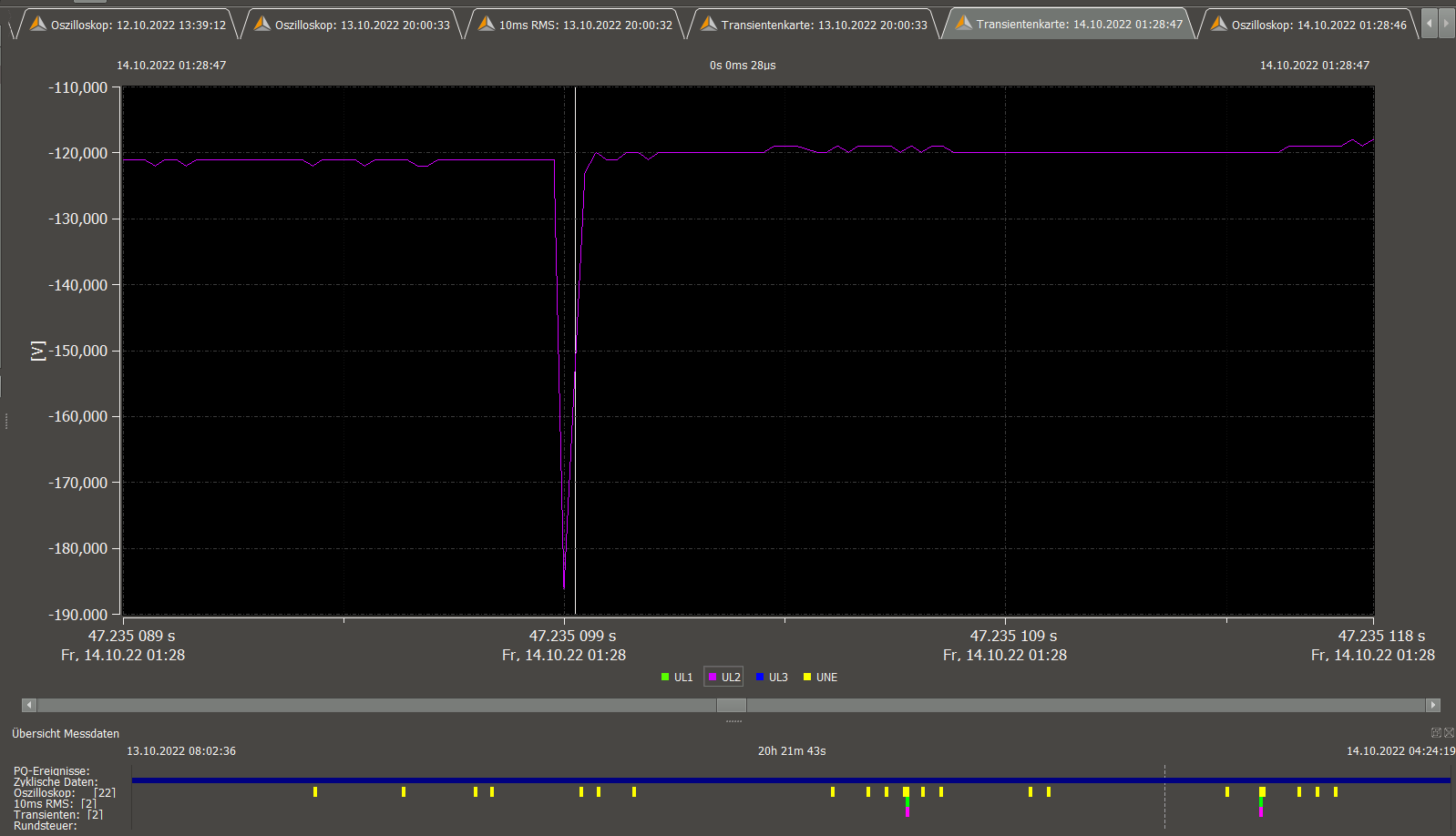
voltage UL2 spike ca. 1us at 47.235099s, resolved to -70V