virtual memory problem for Tru64 (May05-Sep05)
Whats the problem? (shortly)
We own a GS1280 from HP, which has 128GB memory. If one uses more than
about 15GB memory (depending from file I/O) the machine
becomes very slow,
some processes can hang or be killed because of filled swap whereas there
is still lot of free memory and borrowed UBC (30-80GB).
Problem is fixed by the latest kernel patch. There
are only some minor problems left, which can be handled.
Thanks to Han (Sep05).
Whats this page for?
First its for users asking me, why they are disturbed using our
"super"-computer. Second its for our colleagues which just want to know
what HP is playing with its customers. Third its a probably helpfull
report for Tru64 users or other interested people having similar problems.
Last but not least its just for me, remembering how frustrating
it is to communicate with HPs software support. Feel free and correct me,
if I am completely wrong.
News (Mai 24, 2005)
First we set vm_page_prewrite_target to 32K to avoid other effects.
We also want UBC with lowest priority (ubc_borrowpercent=ubc_minpercent=0).
What should happen if (free-pages<2*vm_page_prewrite_target)?
1. get pages from ubc (very fast)
2. steal free pages from other RADs (fast)
3. get borrowed pages from ubc of other RADs (fast)
4. swap out pages (slow)
But what happens:
1. steal free pages from other RADs (failes without vm_overflow patch if >3RADs)
2. get pages from ubc to slow (not quite sure, fixed with vm_overflow?)
3. _no_ pagestealing from other RADS ubc -- Thats the big problem!
4. swapping (starts already on 2.)
=> swapping where a lot of free (incl. borrowed ubc)
memory is on the other RADs
Workaround but with slow file-I/O:
set ubc to minimum, by setting ubc_maxpercent=1 (not desired)
set vm_page_prewrite_target large enough (32k)
Solution:
kernel patch
Details
C-program to reproduce the misbehavior.
Log-file for our GS1280, Tru64-V5.1B-PK4
and UBC-Patch installed.
Please see below for a newer and better version.
Swap (36GB) is configured in lazy mode, because
more swap than memory (128GB) needed for the eager mode
would be a wast of recources. If you have questions ask Joerg Schulenburg,
who has detected these problems and reported it to HP.
You need a C Compiler, vmubc and Tru64 to reproduce the kernel bug.
Here are the facts:
- If you alloc and use more than about 5GB memory, used swap
is increasing slowly and often pagein is increasing too beside
there is more than enough free memory.
Sometimes (after UBC-patch installation?)
I observed also pageout, but not in every case (before UBC-patch).
-
The swapping starts earlier if your application consumes more memory.
For 5GB after around 3 write cycles of the test program, for 12GB
on the second write cycle.
-
If other big memory jobs are running at the same time on other CPUs
they can also be increase the used swap instead of the test program
(see at rss and vmsize of top).
-
Swapping does not start at a fixed memory value. It varies from
test to test. Sometimes it occours after writing to the allocated pages
the second time, sometimes on the last GB in the first cycle already.
-
Used swap stops growing if its size is about the memory demand of
the application or if swap is full. For the last case the program
will be killed even if RSS was already greater than swap space.
-
Machine will become very slowly because of the high swap activity.
Be careful reproducing our tests! As long as the application is running
it will not stop swapping (for ever?).
-
Updated: Programs with high disk activity (reading) can cause swapping, because
system allocates UBC-pages for caching disks and does not free it,
if other RADs need memory. Also UBC consumes memory on low memory conditions.
-
After killing the test program, swapspace is not freed sometimes.
-
Even memory disk can be swapped out and it looks as it pages for ever.
-
Same problem seems to exist for a GS160 (12G mem, 24G swap, not patched, lazy mode).
I could not test it under clean conditions, because machine is heavily loaded.
May be I can test it later. Swap was growing very slowly instead of
decreasing the UBC (summed over all RADs).
-
Setting the undocumented parameter cpus_in_rad to 2 and reboot
(sysconfig -q generic cpus_in_rad) seems to shift the trigger value
from 5GB to 15GB.
-
Using
vmstat -R you can observe how memory gets stolen
from the neighbouring RADs. Swapping starts after four RADs
are filled and the free memory of one of this RADs becomes very small.
If there is no swap device defined, the system becomes very slow too.
Updated:
All together I think the bug is in the page steal algorithm.
If the free memory of a RAD goes down, for some unknown reason pages
can not be stolen from the other RADs which still have free pages
and the vm_rss_block_target limit triggers blocking of the process.
Some inactiv marked pages of that RAD
are paged out. This happens again and again letting the swap grow.
And together with the weakness of Tru64 to never get back a swapped page
to free memory pages you can get a swapping machine with lot of free memory
as a worst case scenario. That way the buggy RAD system makes a HP-NUMA with
128GB memory and 32 CPUs as slow as a PC with 4GB memory and 128GB swap for
big memory jobs.
I found no usefull documentation and no system variables about page stealing
from other RADs. HPs support did fix this first Problem, but there are more
problems. A problem with giving back borrowed UBC still causes the machine to
swap if it is not necessary. Any help is welcome.
History of the bug
I wrote this report because communication with HPs support is a nightmare.
Buying a expensive machine, selling lot of money for support and getting
no sufficient help. This is an excerpt of events, which may be connected
with the kernel bug.
- June 2003: a GS1280, 32CPUs, 128GB memory is installed and ready for use
for our scientists, operating system is Tru64-5.1B,
- July 2003: swap (35GB) full because swap is allocated in advance
in eager mode, switched to lazy mode, applications can
allocate more than 35GB now
- July 2003: seeing a 64GB memory disk swapped out (76GB swap), killing some
processes to get more free memory but swapping does not stop whereat 12GB
are free available, calling HPs support
- July 2003: Call 3724224RE answer from HP: problem is categorized as
tuning problem and not included in the software support, we have to pay
extra for it, but we refuse such kind of help
- July 2003: doing some experiments, as I noticed 3% used swap, whereat
80GB memory are used and 40GB memory are free available, found
growing swap activity by adding and using a 32GB memdisk (8GB free!)
- August 2003: two crashes, today I dont exclude a coherence between
high usage causing unnecessary swapping and that crashes, switching
off all unwanted deamons (which could also swapped out) to reduce
usage as much as possible
- January 2004: again, massive swapping, largest process took 23GB
memory, 64GB used, 48GB free but used for UBC (disk cache),
taking UBC as cause for the problem into account, further tests
- March 2004: crash (panic (cpu 0): mcs_lock: time limit exceeded, also
SCSI errors), disk replaced (was it really defect or just notified as
defect from the buggy kernel?)
- April 2004: after a high load week end lot of correctable error events
in the log, taking into account high syscall activity processes
and reduce syscall activity to test it
- July 2004: again a disk is notified as defect and replaced
- Oct. 2004: after heavy load lot of different nonreproducable crashes,
hints that the problem may be connected with the high load
are ignored by HPs support and hardware errors assumed
- Nov. 2004: memory replaced
- Dec. 2004: crashes, crashes, crashes ..., board + memory replaced
- March 2005: again 34GB free memory but machine is swapping and
processes are killed because of missing swap space,
thinking that the UBC which uses the free memory is the reason (but
today I know there were more bugs which interfere,
making analysis difficult)
making some tests with a simple program
reading big files (70GB) to the memory (40GB), machine crashs
after hours running the test program
- March 2005: be sure that I detected a kernel bug and called HPs
support again, telling about the tiny trigger program
(disk to mem reader); HP tells me to
apply the latest patches and I do so, problem remains
- March 2005: reducing the program to write memory only (memeater)
and observe
swapping after filling the 6th GB with numbers, seeing
the program becomming very slow and massive swapping on 57th GB,
telling HP about that facts and exclude UBC as a swappng reason
- March 2005: getting some curious statements from HP,
first: its not a bug, Tru64 is designed to work so (heah?),
second: please use nmadvise for large memory applications
(its slower and how to do so for third party software?),
third: HP's NUMA is not NUMA (not for applications using
more than one RADs memory (which is 4GB)) --- not a joke! ---
I was complaining about that statements and demand to fix the kernel
bug. The answer was, that its not a bug but a suboptimal
adaption of Tru64 to HP's NUMA, so its look like HP is trying to play
against us.
- March 18th, 2005: I was informed by HP about a hidden kernel option
which could set the number of CPUs per RAD to 2, so there is twice
as much memory per RAD available. The trigger value for the problem
seems to be shifted to higher values and memory access is about 40%
slower for less-than-4GB applications. Engeneers are working
on a n-CPUs-per-RAD patch especially for us.
- March 21th, 2005: crash again, this time a software bug is
taken into account, switching off ARMTech deamon, swapping problem
is still there
- March 31th, 2005: call HP again and asking what they plan to do,
I got the original statements (see above) from the american support
team again.
- April 4th, 2005: getting an nmadvise sample from HP, I corrected
some bugs in it and tried it out. Also tried out disabling
any swap space, but system became very slow instead of paging.
- April 14th, 2005: getting a Customer-Specific Patch Kit which
introduces the kernel parameter vm_overflow. System swappes
only a small number of pages out but becomes very slow if
writing on the 15th GB (99% cpu for kernel, 1% cpu for the process).
Report it to HP.
- April 15th, 2005: getting some calls and emails, which give me the hope,
that HP is reconsidering their meaning about the (non-)bug.
- April 18th, 2005: searching for other people, who could help on
http://forums1.itrc.hp.com/service/forums/questionanswer.do?threadId=859125
- April 19th, 2005: reboot and did some tests with the
patched vm_overflow option,
Do not know how usefull the results are because of using
system()-calls to make the output more usefull (see pitfalls).
vm_overflow seems to reduce swap usage, but nevertheless the system becomes very slow at the
16th GB where free_of_oneRAD becomes minimum (10pages).
- April 22th, 2005: Try to use getrusage instead of system call, see usage.ru_idrss, usage.ru_isrss
growing over all loops (see example log below).
- May 9th, 2005: Got new patchkit
(Fixes to vm_overflow & page migration).
Did some tests withe the old kernel, seeing paging (swap) system with
12M free pages for both vm_overflow variants.
After applying the new patch the memeater got 90GB for the first time without
heavy paging.
Great step to success, but still little paging (swap=100 pages, 48GB free).
Found vmstat.acti raising if free touches 2*vm_page_prewrite_target (maybe ok).
- May 10-11th, 2005: Trying out different configurations of
vm_overflow, ubc_* and vm_page_prewrite_target, looking for paging and
page stealing and asking support about details. Found out, that high
vm_page_prewrite_target delays paging.
- May 17th, 2005: Got important answer. Pages overflow to the next RAD
if free_pages < 2*vm_page_prewrite_target (not documented elsewhere).
- May 24th, 2005: Doing experiments with UBC. Explore that pages are
not stolen from other RADs if memory is borrowed by the UBC.
Notify the Support. Big missbehaviour!
- May 26th, 2005: Calling support again. Emphasize importance.
- May 30th, 2005: Find our machine paging heavily (30GB free, 29GB swap).
- Jun 1th, 2005: Resetting all kernel parameters to sys_check
recommendations, requested by support. Problem remains.
- Jun 14th+15th, 2005: HP expert met, new patch,
problem confirmed (see log), cpu_in_rads=32 as workaround
- Jul 01th, 2005: got a new patch
- Jul 04th, 2005: tried new patch, still unneccessary page outs,
details on Fig. 8, let users login
- Jul 05th, 2005: found machine with 2.5GB In-use swap and 14GB free,
vmstat.free=3143..83K, ubc filled,
switched back to workaround cpu_in_rads=32
Explanations
- RAD (Recource affinity domain)
- To let the Tru64 aware of the NUMA
archtekture, there is one RAD per CPU and 4GB memory belonging to
that CPU. Each RAD has its own paging scheduler. If the memory
of the RAD is consumed, memory pages from the neighbouring
RADs are stolen. The application should not be aware of that, beside
of the access time to the nonlocal memory will be a bit slower.
So memory appears to be flat from users side as expected on
NUMA machines likewise on real SMP machines
(HPs support told me otherwise but I am sure they are wrong).
- UBC (Unified Buffer Cache)
- To speed up (slow) disk operations, (faster) memory can be used as
buffer cache. Part of the UBC is called borrowed, so unused memory
can help to speed up disk operations.
Borrowed UBC is given back on low memory conditions.
Paging should not occour as long as there are
borrowed UBC pages, as stated in the sys_attrs_vm man page.
Because the RAD implementation is buggy, it fails on NUMA systems.
- nmadvise
-
is a routine within the numa library. Its possible to tell the kernel
to distribute the allocated memory pages accross a list of defined
RADs. Its the only way to work around the kernel bug. You also have to
avoid that other processes steal memory from one of this RADs.
So all processes have to care about the NUMA specifics. I think its fine
that this fine tuning is possible, but telling the user that he has to
use that specific thing all the time is not amusing.
- Tru64
-
is as far as I know developped by DEC as Digital UNIX.
DEC is assimilated by Compaq 1998 and 1999 the UNIX
was renamed by Compaq. Compaq is aquired by HP 2002.
- GS1280
- is an multiprocessor system based on alpha chips which have
a very good interprocessor connection and makes nonlocal memory access
very fast. Every alpha chip has 4GB local memory and 4 ways to its
neighbour processors and their memory. This is a 2D-NUMA concept.
32 CPUs are connected in a 4*8 Torus and can access the whole 128GB
memory (thats the theory).
- pitfalls
- Hunting the bug I did some stupid things. I added syscalls to the
test program calling date, ps, vmstat, swapon after writing avery GB.
Thats a bad idea, because system usually calls fork and exec. Fork
doubles the process inclusive memory. I saw the system calls becoming very slow
and of course that has influenced the measurements.
Also you have to define __mingrowfactor (see man malloc) to avoid, that
libc allocates 10% of the actual process memory instead the wanted place which
can has additional side effects.
- Testprogram vmbug4.c:
-
#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
#include <time.h>
#define ALLOC_SIZE 1024 * 1024 * 1024
int main (int argc, char *argv[]) {
int index, chunks, cycle;
char **buf;
time_t t1, t2;
if (argc != 2) { printf(" usage: %s memory[GB]\n", argv[0]); exit (1); }
chunks = atoi (argv[1]); setvbuf (stdout, NULL, _IONBF, 0);
buf = malloc (chunks * sizeof (char *)); assert(buf);
printf (" alloc memory:");
for (index = 0; index < chunks; index++) {
buf[index] = (char *) malloc (ALLOC_SIZE); assert (buf[index]);
printf (" %dGB", index);
}
for (cycle = 0; cycle < 200 ; cycle ++ ) {
printf ("\n fill memory cycle=%d:",cycle);
for (index = 0; index < chunks; index++) {
t1 = clock();
/* Zero fill memory to allocate pages*/
memset (buf[index], 0, ALLOC_SIZE);
t2 = clock();
printf (" %dGB %dms", index, (int) (t2-t1)/1000);
}
}
printf ("\n");
}
- Example logs (April 14th):
-
Here the results, before the vm_overflow patch was installed.
After a reboot, the test was started using 1, 3, 4, 5, 6, 8, 12, 13, 14, 15,
16, 20 and 60GB. Problem becomes hard from 16GB and higher.
I startet the program with
runon -r 26 and observed the
activity using xmesh, vmstat -R, top
and ps aux.
CPU array, neighbours of RAD 26:
17 19 21
24 (26) 28
25 27 29
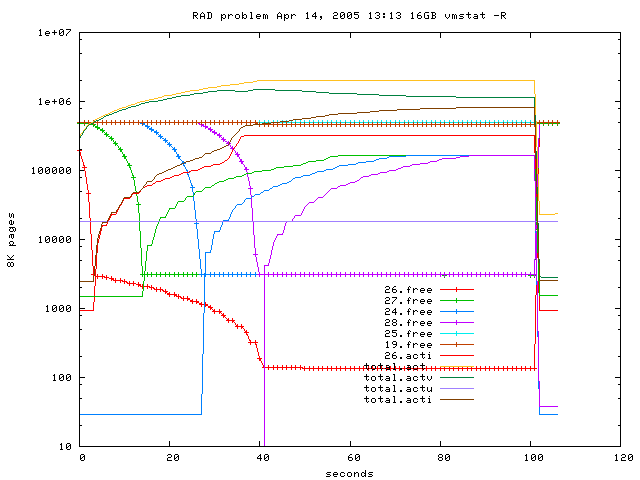
Fig 1: Free pages of involved RADs over time during the experiment,
sources: gnuplot-file and
vmstat-R-log
On Fig 1 a 16GB test is shown. First RAD26 hit the limit of
2*vm_prewite_target=3072(?) where page stealing from RAD27 (lower neighbour)
starts. But further pages are taken from the RAD26 free list which probably
causes filling of the inactiv list (sence not clear).
If RAD27 has given its free pages to RAD26, free pages from RAD24 (left
neighbour) get stolen. After that pages are stolen from RAD28 (right
neighbour).
The inactiv lists of RAD26, 27 and 24 start above zero because the
previous runs left them populated. After 40 seconds 4 RADs a 4GB are
filled but the inactiv lists still grow for unknown reason.
25K pages were stolen from RAD19 (upper neighbour).
Only 133 pages are left in the free page list of RAD26.
After 100s the memeater program was killed by me.
So why inactiv list is populated? Does it have an important influence
to the misbehavior shown below?
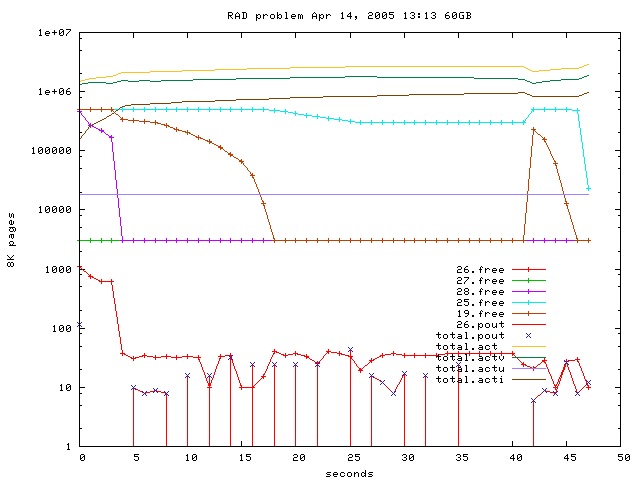
Fig 2: Free pages of involved RADs over time during the experiment,
sources: gnuplot-file
and vmstat-R-log
After the 4th RAD (RAD28) is filled the number of free pages on RAD 26
drops below 40 pages and paging starts (4*4GB=16GB touched).
Until here every GB is written in about 1-3 seconds.
Now the writing speed goes down dramatically and 40s later the program
is nearly blocked (pcpu is less than 2%). After 5 minutes I started
a dumpsys (Thu Apr 14, 13:28 vmzcore.4 666MB + 18MB vmunix.4).
No further vmstat available because this terminal was hanging.
Seems that only 5 RADs are involved. That would be a explanation
for having no such trouble on a GS160 which has only 4 RADs.
terrible slow, ps aux shows over 90% pcpu for kernel activity.
13:16 cycle0: 16th GB steht top<2% vsz=61.2GB
14:05 cycle0: 27th GB pcpu=2.4% rss=29G kernel=87%cpu26 free=90GB
14:49 cycle0: 37th GB pcpu=1.8% rss=39G kernel=97%cpu26 free=80GB
14:56 Ctrl-C -> swap=249
- Example logs (April 19th):
-
Did some tests with the patch, see vmbug4.log.
- Example logs (Jun 11th) vm_overflow=1:
-
Working condition, 68GB stated as free. According to the sys_check
recommandations ubc_borrowpwercent=20 (pages= 105K/RAD, 3355K/total),
vm_page_free_target=2048 and vm_page_prewite_target=4096 was set.
runon rad26.
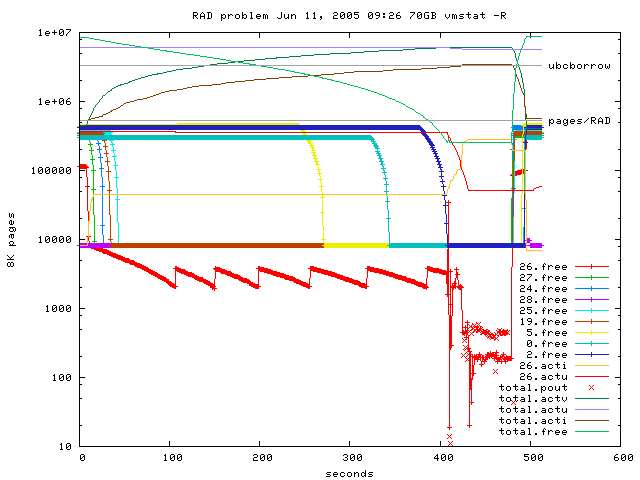
Fig 3: Free pages of involved RADs over time during the experiment,
sources: gnuplot-file
and vmstat-R-log,
Values above 1K are rounded to Kilopages.
20GB OK (not shown).
40GB OK (not shown).
70GB until RAD2 (most distant RAD) free pages used, actu.rad26 ok,
after 64GB paging, stopping with ^C,
On logfile line 9440 RAD26.free jumps from 2k to 3.8K. Why?
Transfered to RAD5?
Only the actu value of RAD26 (the home RAD) goes down after all
available free pages are consumed. Most part of ubc pages appear as
inactive pages.
Other RADs do not spent ubc pages. Do not give borrowed ubc back
is not expected on usual shared memory systems.
Please have in mind, that first page outs apear before borrowed
ubc pages are given back. This is in contrast to the man page of
sys_stats_vm. Also notice, that when RAD26.actu goes
below ubc_borrowpercent paging is remarkable high.
paging (not swap but mmap?) of other processes dont stop! (pcpu still 2%..60%
of some users after 30min, another bug?)
- Example logs (Jun 15th):
-
After reboot, clean machine, UBC filled by reading files from disk using
dd (slow because reading fragmented files parallel).
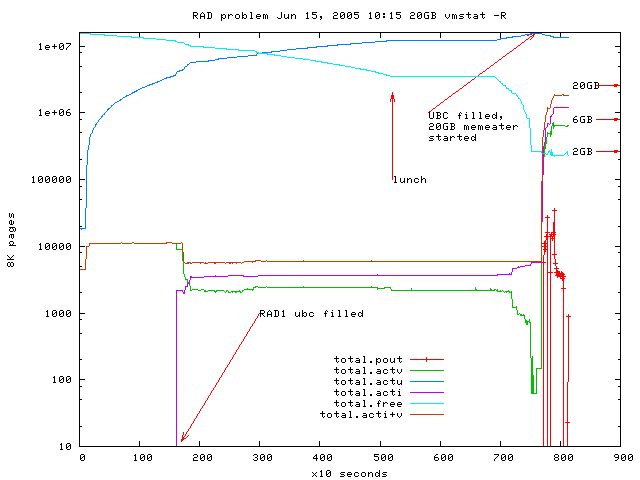
Fig 4: filling the ubc and starting 20GB memeater causes nonregular paging,
sources: gnuplot-file
and vmstat-log
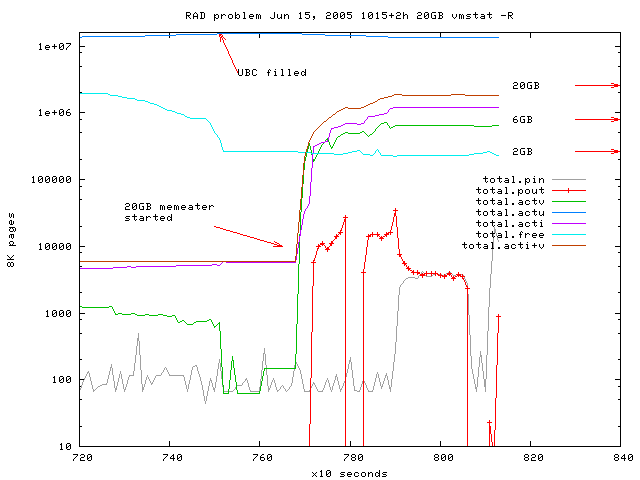
Fig 5: right part of Fig. 4, ubc filled,
starting 20GB memeater causes nonregular paging,
sources: gnuplot-file
and vmstat-log,
Work around:
Now kernel patched, switched to 32CPUs/RAD (1 RAD only),
no UBC problems expected,
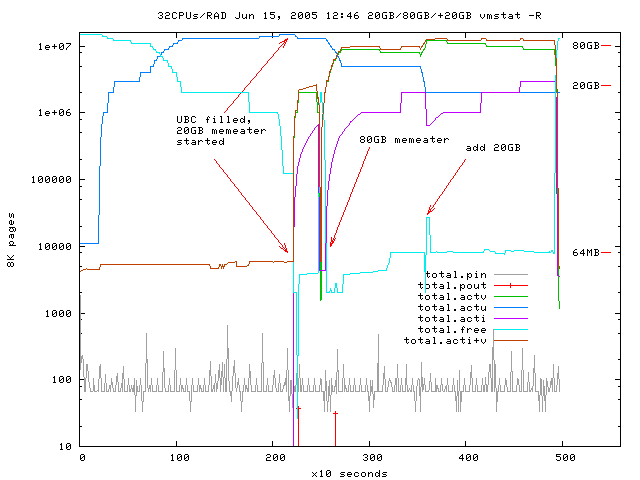
Fig 6: filling the ubc and starting 20GB, 80GB and additional 20GB memeater
without excessiv paging,
sources: gnuplot-file
and vmstat-log
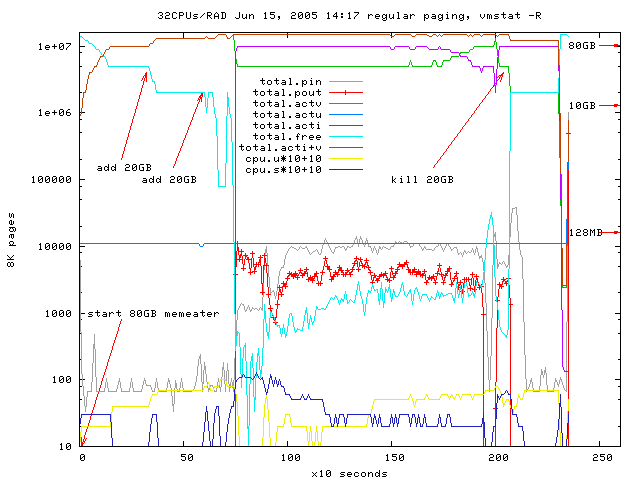
Fig 7: force regular paging just for fun, pin is much bigger than pout,
sources: gnuplot-file
and vmstat-log
- Example logs (Jul 04th):
-

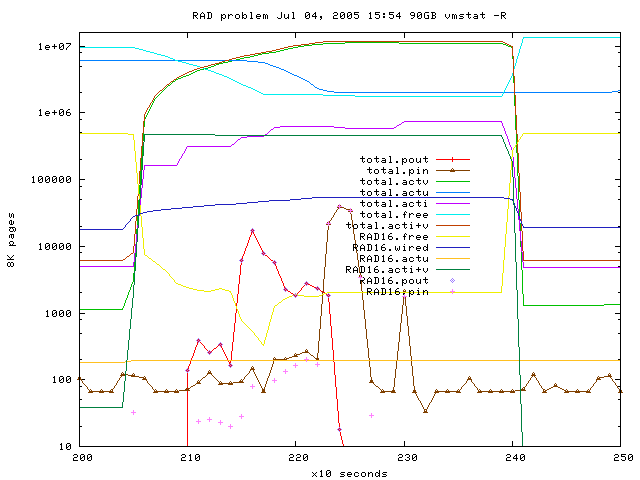
Fig 8: after the new patch applied paging happens later but the reason
is unclear to me because vm_page_free_min=20 was not hit
(RAD16.free was 2418 on the first page out, other RADs had 19K..275K free),
also there was still enough free remote memory,
sources: gnuplot-file
and vmstat-log
Criticism
- Support
-
1st: Level 3 support (sounds great) reached.
Still email communication via Level 1 (?) support.
L1 Support forwards modified emails without sending a copy to
me, so I dont know what information L3 is getting and sending.
Everything is filtered. 2nd: One kernel bug already explored,
customer seems categorized as a PEBKAC, support still assumes,
that problem is just a tuning problem.
Blind confidence in HP software (sys_check).
- ITRC Forum
-
No responses from the developping team. Proposals
which improve Tru64 are not taken serious.
- Tru64-Kernel
-
Undocumented or bad documented RADs (sys_attrs_vm only valid for 1 RAD).
Undocumented kernel parameters (ubc_overflow, cpus_in_rad).
Nonsensical default configuration (vm_swap_eager=1).
Unneccessary complexity of the kernel (vm_swap_eager, ubc_overflow),
less complexity means less bugs, easier support.
No sources available, which would be not a problem if
customers are taken seriously. Swap can be added on runtime,
but not released on runtime, making debugging expendable (reboots).
Joerg Schulenburg, 2005, Administrator (inquire more details if you want)