Gewoehnlich mache ich meine Backups mit rsync abwechselnd auf 2
verschiedene USB-Sticks, teilweise remote via ssh.
Das ist sehr flexibel nutzbar.
Mann muss sich zwar ein bischen disziplinieren, um die persoenlichen
Datenmengen nicht zu stark wachsen zu lassen, aber Flash-Sticks sind
guenstig, ausreichend schnell und gut zu verstauen.
2016 habe ich dann mal wieder alle Backup-Daten bzw. die CRCs
der Datenbloecke verifiziert (rsync -n -c ...)
und musste auf einem der 16GB-USB2-Sticks
bei fast 2 Jahre alten Dateien und Verzeichnissen
Bitfehler (ca. 50% der Bytes einer Flash-Page hatten 1-2 Bitdreher)
feststellen.
Der Fehler war mit fsck + rsync -c schnell behoben, aber wie sichert
man sich gegen Bitflips, wenn man nur den Backup-Stick verfuegbar hat?
Zur Zeit gibt es da nur wenig Moeglichkeiten:
md5sum aller Dateien (Extradateien),
btrfs und zfs (nur neue Systeme, mit CRC fuer Datenbloecke).
Am bewaertesten (simple and stable) sollte aber Software-RAID6
mit mdraid auf mindestens 4 Sticks sein. Das habe ich getestet.
Vorteile von mdraid sind, das es einfach genug ist, um ggf. per
Hand zu reparieren und nur etwa 5-6MB Memory benoetigt (KISS).
Der Teufel steckt aber wie immer im Detail:
Probleme mit Kabeln, Hubs und schlechter Firmware, low write speed.
RAID behandelt urspruenglich leider nur Hardwareausfaelle bzw. durch
Hardware gemeldete Datenfehler.
Stille Bitflips (bit rots, silent data corruption) lassen sich zwar mit
RAID6 (auch RAID1,RAID5) erkennen, aber dazu muss erst ein spezielles
Scrubbing angestossen werden (echo check > /sys/block/md0/md/sync_action) und
anschliessend ein Register mit der Zahl
defekter Bytes ausgelesen werden (cat /sys/block/md0/md/mismatch_cnt).
RAID6 kann theoretisch auch den korrupten Chunk im Stripe erkennen
und koennte damit die Daten wieder restaurieren, solange nur
ein Chunk betroffen ist. Genau diese Faehigkeit moechte ich nutzen, um
Bitflips lokalisieren und korrigieren zu koennen.
Bei normalen Leseoperationen werden Bitflips von mdraid aber nicht entdeckt
(Test: parity-Block geloescht, ToDo: Test Datenblock-Bitflips).
Man kann dann solche Fehler auf einem Medium korrigieren lassen, aber
erfaehrt leider nicht, auf welchem Stick und wo der Fehler zu finden war.
Nachtrag: sync_action=repair schreibt nur neue Parities von ggf. schlechten
Daten. Nur das in neueren Versionen der mdadm-sourcen
vorhandene Tool raid6check aus mdadm-v3.3++ kann die "bit rots" nicht nur
lokalisieren, sondern auch korrigieren.
Material:
- Test-Sticks: 4 verschiedene 4GB-USB2-Sticks (read 15-18MB/s, write 4-9MB/s, 30-60mA)
alle einzeln am Hub auf Fehler und niedrigen Verbrauch getestet (Summe unter 350mA)
je eine 512MB-Partition ab 2040K (md-header = 8K) eingerichtet
- passiver 4-Port-USB2-Hub (Genesys Logic?) mit miniB-Buchse mit verschiedenen Testkabeln (3mm/5mm)
oder passiver 3Euro-4-Port-Hub (Terminus Tec.) mit 10cm langem 3mm-Kabel
(billige Hubs mit kurzen duennen 3mm-Kabeln sind besser, als welche mit langen duennen 3mm-Kabeln)
Firmware kann sich nach I/O-Fehlern aufhaengen, dann teilweise Power-Off noetig
ToDo: Wird duennes USB-Kabel durch externe Stromversorgung ausgeglichen?
nein (wahrscheinlich fehlende Verdrillung fuer flexiblere aber
HF-technisch schlechtere Kabel)
- 7W 10R Lastwiderstand, DVM (Dig. Voltmeter), Oszillograph, diverse Kabel
USB-Voltmeter Gembird EMU-01 Bemerkung: Shunt=0R5
hier schien billiger besser zu sein, leider waren 2 nachgekaufte Geraete Schrott (bis 0.2A/0.2V laufende Schwankungen der Messwerte)
USB-Voltmeter DeLock 65569 Bemerkung: misst nur 1/s und mittelt 3-4 Messungen, Strom erst ab 100mA, Shunt=1R?
beide nur in 10mV/10mA Schritten, bei mir 3 Geraete 30-80mV zu wenig
Messung der Kabel mit 2A-Netzteil-Testkabel(ggf.incl.Hub)-10R-Lastwiderstand
mit DVM oder USB-Voltmeter davor, wenn Spannung unter 4.6V ist, sind Probleme wahrscheinlich
z.B. OK: 4mm*2*75cm-Kabel(4.71V), 5mm*50cm-Kabel+Hub(4.73V)
z.B. BAD: 4mm*3*75cm-Kabel(4.56V), 3mm*75cm-Kabel+Hub(3.92V)
- (altes) Linux-2.6.18 + mdadm-2.6.9 (2009-03)
(neues) Linux-3.2.0 + madm-3.2.5 (2012-05)
Results: Size= 2*512MB + 2*512MB Parity 512KB-chunk-size=1024*512B
mdadm --create /dev/md0 --level=0 --raid-devices=4 /dev/sd[b-e]1 # 0.9min (8MB/s)
cat /proc/mdstat /sys/block/md0/md/mismatch_cnt
mdadm --stop /dev/md0
mdadm --examine /dev/sd[b-e]1 # info
mdadm --assign /dev/md0 /dev/sd[b-e]1 # bind to md0
echo 8192 > /sys/block/md0/md/stripe_cache_size
Speed:
dd if=/dev/md0 bs=1M count=100 of=/dev/null iflag=direct # 29 MB/s read
dd if=/dev/md0 bs=1M count=100 of=/dev/null # cache=0 44 MB/s read (42MiB/s)
dd of=/dev/md0 bs=1M count=100 if=/dev/zero seek=256 oflag=direct # 5-6 MB/s
for x in 256 1024 4096 8192 16384;do
echo $x > /sys/block/md0/md/stripe_cache_size
dd of=/dev/md0 bs=1M count=100 if=/dev/zero seek=256; done
# 256KB 2.1-2.3 MB/s write (default)
# 1MB 3.8-5.2 MB/s write
# 4MB 5.9-6.1 MB/s write
# 8MB 7.2-7.6 MB/s write
# 16MB 2.4-5.5 MB/s write
# ToDo: other stripe size? (4GB-flash-page ca. 128*4K=512KB fits good)
# write speed varies
Test: overwrite-parity-sector + sync_action=check + sync_action=repair OK
# write 2*512KB test sequence (512K=0x80000)
for x in $(seq 65536);do echo -en "0A01____";done|dd of=/dev/md0 seek=0
for x in $(seq 65536);do echo -en "0B02____";done|dd of=/dev/md0 seek=1K
for x in $(seq 65536);do echo -en "0C03____";done|dd of=/dev/md0 seek=2K
for x in $(seq 65536);do echo -en "0D04____";done|dd of=/dev/md0 seek=3K
dd if=/dev/sdb1 count=2048 skip=1024 | hexdump -C # after stop + assemble (syncing)
# 512kB Data01 + 512KB Data04 ... on sdd1=dsk1
# 512KB Data02 + RAID5-Parity ... on sdc1=dsk2
# RAID5-Parity + RAID6-Parity ... on sde1=dsk3
# RAID6-Parity + 512KB Data03 ... on sdb1=dsk0
# start silent bitflip-test
dd of=/dev/sdd1 bs=1K count=1 seek=512 if=/dev/zero # zero 1KB data disk1
dd if=/dev/sdd1 bs=1k count=1K skip=512 | hexdump -C # 1KB zeros
dd if=/dev/md0 bs=1k count=1K | hexdump -C # 1KB zeros
cat /proc/mdstat /sys/block/md0/md/mismatch_cnt # 0 Errors
echo "check" > /sys/block/md0/md/sync_action # 3.2min min.1MB/s/disk
cat /proc/mdstat /sys/block/md0/md/mismatch_cnt # 8 Errors (why 8? 1K or 2K zeros)
dd if=/dev/md0 bs=1k count=1K | hexdump -C # 1KB zeros
cat /sys/block/md0/md/rd?/errors # 0 errors
/sbin/mdadm --detail /dev/md0 # clean!
echo "repair" > /sys/block/md0/md/sync_action # 3.5min incl. check
dd if=/dev/sdb1 bs=1k count=1K skip=512 | hexdump -C # read real data
# 512kB Data01 + 512KB Data04 ... on sdd1=dsk1 Data01=corrupt
# 512KB Data02 + RAID5-Parity ... on sdc1=dsk2
# RAID5-Parity + RAID6-Parity ... on sde1=dsk3 Parity from corrupt-data
# RAID6-Parity + 512KB Data03 ... on sdb1=dsk0 Parity from corrupt-data
--- experiment failed ---
# "repair" just recomputes parities from bad data for v2.6.9 and v3.2.5 (2012-05)
# ChangeLog-v3.3: v3.2.2 has undocumented unfinished raid6check (GitHub)
# download mdadm-3.2.5 + mdadm-3.4 (latest 2016-01) + make raid6check
# raid6check failes on lx2.6.4 (Error reading sysfs info), lx3.2.5 OK
./raid6check /dev/md0 0 4 | grep -i error # detects silent error correct
# ... but how to repair stripe 0? try latest version
# Error detected at 0: possible failed disk slot: 1 --> /dev/sdc1 # 3.2.5
./raid6check /dev/md0 0 4 autorepair # v3.4 (since v3.3 2013-09)
# Error detected at stripe 0: possible failed disk slot 0: 1 --> /dev/sdc1 # 3.4
# Auto-repairing slot 1 (/dev/sdc1) # simple to repair one chunk
dd if=/dev/md0 bs=1k count=1K | hexdump -C # 1KB zeros, bad-data+bad-parity
-- Yeahh! next step is to add --verify-on-read to mdadm --
-- silent bitrots detected and corrected successfully --
-- thanks to the author Piergiorgio Sartor for the great improvement
# ToDo: what about --examine-badblocks? s2disk failes?
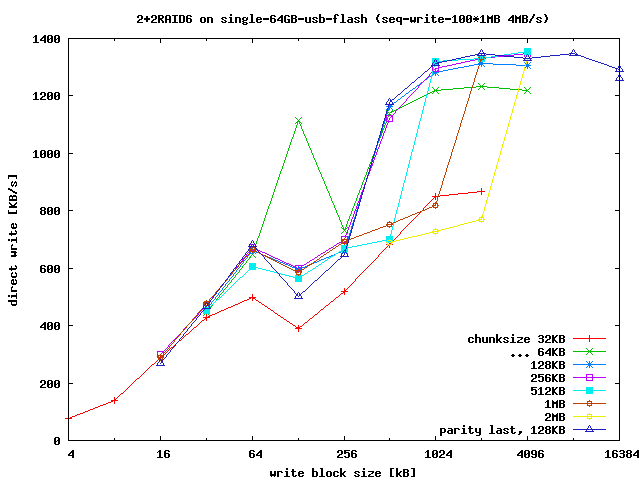
Test 4+0raid0: write 12-16MB/s (2*16MB-blocks) = 4*4MB/s OK sd[bcde]2
Test 5+2raid6: r50MB/s w2..8MB/s (in progress, chunk=128K)
Vorteile Stick-RAID gegenueber einzelne SSD?:
- transparente selbst waehlbare Redundanz (bei SSD intern, fix)
- bei Fehler Sticks einzeln preiswert ersetzbar (ewiges Leben der Daten)
- geringere Anfaelligkeit gegen Totalausfall durch Firmwarefehler
Nachteile Stick-RAID gegenueber einzelne SSD:
- bei gleichem Preis ca. 8*langsamer, halber Speicherplatz (2+2RAID6)
- Stromverbrauch?
Hinweis: Es gibt da eine schoene Dissertation von David Jacob aus Virginia aus dem Jahr 2009 im Web ueber RAID-6 mittels FPGAs. RAID6 ist Weltraumtechnologie und kann der einfachen Strahlungshaertung von normalen Speichern dienen (radiation hardening). Ein md-raid-Modus mit Parity-Check bei jeder Leseoperation ist eine durchaus nuetzliche Sache (Linux in strahlengehaerteten Billig-Robotern). Das fehlt 2016 noch in mdadm.
Nun ist das rumschleppen von mindestens 4 Sticks und einem Hub
manchmal unpraktisch. Geht es mit weniger?
Ja, mit mehreren Partitionen auf einem Stick.
So kann man auch mit 2 Sticks mit je 2 Partitionen auch ein 2+2RAID6 fahren.
Es kann dann ein Stick (physisch) ausfallen oder einzelne Bitfehler
koennen detektiert und korrigiert werden (siehe oben).
Der Minimalfall mit mindestens 4 Partitionen auf nur einem Stick und 2+2RAID6
schuetzt immernoch vor Bitfehlern. Das will ich hier testen.
Nachteil ist, dass die Kapazitaet und Schreibgeschwindigkeit
sich reduziert (mindestens um 50% bei 4 Partitionen,
33% bei 6 Partitionen, 25% bei 8 Partitionen, ...).
Dafuer kann man Bitfehler selbst kontrollieren.
Die Lesegeschwindigkeit aendert sich wegen der besseren I/O-Rate
im Gegensatz zu Festplatten (die Speicher mit den drehenden Scheiben
und den hohen Latenzzeiten) kaum.
Aber es gibt einiges zu beachten, um die maximale (Schreib-)Geschwindigkeit
zu erreichen und die Stabilitaet des Systems zu erhalten(!).
Theoretisch sollte der Schreib-Overhead bei zunehmender Partitionzahl
immer weiter sinken. Die Berechnung der Parity kostet bei den heutigen
CPUs kaum Zeit und der Anteil zum Schreiben der Parity sinkt mit hoeherer
Partitionszahl bezogen auf die zu schreibenden Datenmengen.
Da die Erase-Bloecke aber sehr gross sein koennen
(Megabytes auf billigen Gigabyte-Sticks) und
man dann fuer volle Performance immer groessere Stripes konfigurieren muss,
die in einem Stueck beschrieben werden sollen,
muss man bei der Chunk-Groesse Kompromisse machen.
Durch die Partitionierung verwandeln sich sequentielle Schreibzugriffe
aber in Random-aehnliche und mit kleineren Chunks (und Stripes)
sinkt die Schreibrate bei Random-Zugriffen erheblich (z.B. bei 4KB-pages und
4MB-Erase-Bloecken um Faktor 1000,
bei 512KB-chunks und 4MB-Erase-Bloecken um Faktor 8, d.h. USB2-uebliche 5MB/s
Schreibrate faellt auf 0.6MB/s, das ist nur noch USB1-Niveau).
Daher sind Sticks mit hoher Schreibrate bei Random-Writes mit
kleinen Bloecken (ideal bis 512KB oder darunter) besser geeignet, als solche,
die zwar sehr hohe sequentielle Schreibraten erreichen, aber bei random-write
extrem einbrechen. Eine Eigenschaft, die von Flashspeicher-Herstellern meist
nur bei SSDs beworben wird und dort neben der Kapazitaet den Preis bestimmen.
Deshalb muss man hier bei der Chunk-Size Kompromisse machen
und verliert maximal erreichbare Performance.
Tuning-Tips:
Hier fehlen noch Messungen von mir (ToDo)! Der Normalfall, die Parity-Bloecke gleichmaessig ueber alle Partitionen (Drives) zu verteilen (left-symmetric), kann sich beim Rebuild auf Sticks mit Erase-Pages groesser als die Chunk-Size negativ auf den Speed auswirken. Schreibt man alle Parity-Bloecke auf die gleiche Partition, sollte das wegen der quasi sequentiellen Writes Geschwindigkeitsvorteile bringen. (fehlt bei mdadm-v2.6.9-2009-03?)
Vorsicht! Diesen Parameter nicht hoeher setzen, als die Datenrate, die
das System liefert. Bei USB-Sticks die bei RAID random-aehnliche
Zugriffsmuster haben, kann die Schreibrate leicht unter
1 MB/s fallen, welches der Defaultwert ist. Dann sind bei resync keinerlei
normale Operationen zum RAID-Device moeglich. Das kann bis hin zu
Kernel-Ooops fuehren, wie ich selbst erleben durfte.
Den Mindestwert zu reduzieren, ist hier also meiner Erfahrung nach besser.
Da das nirgends dokumentiert zu sein scheint, betone ich dieses Problem
hier explizit.
Wer hoehe ReBuild-Raten braucht,
sollte zuerst die User-Last einschraenken (Quelle des Problems), statt
durch vermeintliche Verbesserungen versehentlich das Problem zu vergroessern.
# Beispiel-Single-Stick-RAID6: # 60.5 GiB-Stick mit 2+2RAID6-chunksize=512KB seq-wr=4MB/s rd=28MB/s # binary units: 1 GiB = 1024*1024*1024 Byte = 2^30 Byte n=4;blk=16;palign=$[60500/n/blk*blk];for x in $(seq $n);do \ (echo "$[((x-1)*palign+blk)*2048],$[(palign-blk)*2048],fd";\ if [ $x -lt $n ];then echo "$[(x*palign)*2048],+,X";else echo ",0,0";fi;\ echo -e ",0,0\n,0,0");done|/sbin/sfdisk -S32 -H64 -uS -x --force /dev/sdb # ensure system stability for low media write rates! echo 100 > /proc/sys/dev/raid/speed_limit_min # default = 1000 [KB/s] echo 8192 > /sys/block/md0/md/stripe_cache_size # 8K * 4KB * n=4 = 128 MB ?? (ToDo) # parity-first: sdb1=P sdb5=Q sdb6=data1 sdb7=data2 # level=6 num_drives=4 chunksize=512KB version=0.90(no data offset) mdadm --create /dev/md0 --assume-clean -pparity-first -l6 -n4 -c512 -e0.90 /dev/sdb[15-7] # resync: partity-first speed = left-symmetric speed on 60GB test-stick # stride=128*4KB=512KB-pages, stripe=2*(stride=512KB)=1MB # ext2 was tested as slower than ext4 without journal mkfs.ext4 -O ^has_journal -b 4096 -E stride=128,stripe-width=2 /dev/md0 mount -t ext4 -o default,noatime,nodiratime /dev/md0 /media/md0 # have fun!