URZ HPC-Cluster Neumann (disassembled 2021)
|
|
 |
Neumann - 100 Teraflop Infiniband-Cluster
Aktuelles:
- Mar2016 - Aufnahme Normalbetrieb, Problembeseitigungen
- ToDo: background-jobs, Application-Checkpointing (failed)
- Mai2016 - Please dont use your home for big data!
This will create problems on the login node.
Always use /scratch/tmp/${USER}/ for big data
and remove files after usage. Disk quota was
set to 2GB at /home 2021.
- Sep2021 - below our switch-off plan (fixed at Nov 25th)
- 25.11.2021 - new HPC system
available for users (10 days later)
- 30.11.2021 - removing user accounts and data
- 07.12.2021 - dissassembling (6 days later)
|
Rechnersystem-Kurzbeschreibung
Mit der Installation des Haswell-Systems der Firma Clustervision
im November/Dezember 2015 steht
den Nutzern unserer Universität ein Rechen-Cluster (compute cluster)
aus mit Infiniband vernetzten Mehrprozessor-Knoten
mit Linux-Betriebssystem und Slurm-Job-Scheduler zur Verfügung.
Der Neumann-Cluster ist für spezielle parallelisierte
Anwendungen mit hohen Anforderungen an Compute-Leistungen bestimmt.
Er löst die älteren HPC-Systeme ab.
Durch die
hohe Netzwerkbandbreite and ausreichend Hauptspeicher ist insbesondere die
Berechnung sehr grosser Probleme auf diesem Cluster effizienter möglich.
Bilder/Images:
Rueckansicht mit Kuehltuer,
Rueckansicht Detail,
Rueckansicht Verkabelung,
Board Inlet,
Board Z10PH-D16
Hardware
| Architektur: |
uniform distributed memory,
172 infiniband-connected 16core-ccNuma-nodes 256 GB/node,
2 GPU-nodes 4 cards/node |
| Prozessor (CPU): |
2 x Xeon E5-2630v3 (Haswell) 2.4GHz L2=8x256KB L3=20MB Boost_AVX=2.6GHz Boost_single=3.2GHz
256-bit-Vector-support (AVX2) 16 FLOP/clock, 610 GFLOP/node (64bit),
4 memory-channels/CPU je 14.9 GB/s, 59 GB/s/CPU, 85 W/CPU
| |
| CoProzessor (GPU): |
GeForce GTX 980 ca. 4TFLOP32bit 156GFLOP64bit,
4GB RAM onboard,
224 GB/s, 180W
4 cards/node, 2lx+1win Nodes
(versus 1.2TFLOP32bit/node, 119GB/s und 170W/2CPUs der Haswell-Nodes)
|
| Board: |
ASUSTeK RS720Q-E8-RS12 1.xx
(4 boards per 2HE-chassis, PCIE3.0x16 128Gb/s) |
| Hauptspeicher (RAM): | 256 Gbytes, 16*16GB-DDR4 ECC
Micron, DDR4-1866MHz=14.9GB/s, 4 channels/CPU, 2 DIMMs/Channel,
Memory-Bandwidth 119 GB/s/Node |
| Festplatten (HD): |
diskless nodes, BeeGFS 4 Nodes je 2*(10+2 RAID6) * 4TB ca. 290TB,
8GB/s, 80*105 IOPs * 4KB, meta: 4*32KIOPs * 4KB |
| Netzwerkanschluss: |
Gigabit-Ethernet (management), QDR-Infiniband (40Gb/s, peak=4GB/s) |
| Stromverbrauch: | 58kW (idle: 16kW) |
| Performance-Daten: | MemStream: 119 GB/s/node, 20.5 TB/s
|
| | MPI: 3.15 GB/s/node (alltoall uniform, but see problems)
|
| | Peak = 103 TFLOPs (40 FLOP/Word, 1.7 GF/W)
|
Systemsoftware, Anwender-Software
- CentOS-7.1, trinity, docker, xcat, slurm-14.03, Modules-3.2
- Fortran, C/C++ gcc-4.8.3 (bis 8.2), openmpi, cuda-7.5.18
- OpenFOAM-2.3
- Before using software please check if usage is covered by the license.
Most commercial software will be for university members or subgroups
only.
These software mostly log its user names and usage on the license server.
- Nutzerverwaltet:
LIGGGHTS(R)/3.3.1,
starCCM+/10.6, 11.02,
OpenFOAM-3.0.1,
Ansys17/fluent,
gnat/4.9.3(gnu-ada),
R/3.3.0,
matlab/R2013a
(Anleitungen bitte ins Uni-HPC-Wiki)
- Fehlende Software kann auch gerne vom Nutzer installiert werden.
Sie bekommen dann Schreibzugriffe und Hilfe bei der
modulecmd-Integration. Bitte per EMAIL anfragen.
- ACHTUNG: Programme mit Floating-Lizenzen koennen im Jobsystem ggf. erfolglos abbrechen,
da zum Ausfuehrungszeitpunkt wegen des Campusweiten Lizenz-Sharings
keine verfuegbaren Lizenzen garantiert werden koennen.
GGf. werden wir nach Ruecksprache Lizenzen fuer den Server reservieren.
- Als Storage (insbesondere fuer parallele Schreib/Lese-Zugriffe)
bitte /scratch/tmp/$USER/ benutzen (beegfs).
/home ist von den Knoten via NFS erreichbar und nur fuer kleine Tests
geeignet (max. 1GB). Bitte wichtige Daten selbst sichern!
Bei Bedarf werden /scratch/tmp/-Verzeichnisse ohne Rueckfragen
geloescht (aeltere volle Verzeichnisse zuerst).
- Compiler und Software-Umgebung auswaehlen
module avail # verfuegbare Software-Module anzeigen (Compiler)
module list # geladene Module anzeigen (echo $LOADMODULES)
module load openmpi/gcc/64/1.10.1 # OpenMPI mit GCC 64bit
module load afni-toolbox # libblas.so.3 + liblapack.so.3
module load joe # text editor besser als vi
# you can put this for your favourite modules to .bash_profile
- Jobsystem: Slurm
- For computations, always use slurm as job manager. It is not allowed
to start computations on the login-node directly, especially to avoid
out-of-memory situations on this important part of the cluster.
- example jobfile job.sh (copy it and adapt it to your needs)
#!/bin/bash
# UPDATE: 22.09.2019 simplification by slurmProlog/epilog-script
# please check http://www-e.uni-magdeburg.de/urzs/t100/ periodically 2016-11
#
# lines beginning with "#SBATCH" are instructions for the jobsystem (man slurm).
# lines beginning with "##SBATCH" are comments
#
#SBATCH -J job-01 # jobname displayed by squeue
#SBATCH -N 4 # minimum number of nodes needed or minN-maxN
# do not waste nodes (check scaling of your app), other users may need them
#SBATCH --ntasks-per-node 1 # 1 for multi-thread-codes (using 16 cores)
##SBATCH --ntasks-per-node 2 # 2 for hybrid code, 2 tasks * 8 cores/task
## # ... [* 2 threads/core]
##SBATCH --ntasks-per-node 16 # 16 for pure MPI-code or 16 single-core-apps
#SBATCH --time 01:00:00 # set 1h walltime (=maximum runtime), see sinfo
#SBATCH --mem 80000 # [MB/node], please use less than 120000 MB
# please use all cores of a node (especially small jobs fitting to one node)
# nodes will not be shared between jobs (avoiding problems) (added 2017.06)
#
# most output is for more simple debugging (better support):
# we are on a 1st node here using sbatch, but on the login node using salloc
# mpirun will not work on the login node because it is in another subnet
#
. /cluster/apps/utils/bin/slurmProlog.sh # output slurm settings, node healthy
#
# load modulefiles which set paths to mpirun and libs (see website)
echo "DEBUG: LOADEDMODULES=$LOADEDMODULES" # module list
#module load gcc/4.8.2 # if you need gcc or gcc-libs on nodes
#module load openblas/gcc/64/0.2.15_no_affinity # multithread basic linear algebra
#module load openmpi/gcc/64/1.10.1 # message passing interface
#module load ansys # Ansys-Simulations, License needed!
echo "DEBUG: LOADEDMODULES=$LOADEDMODULES" # module list
#
## please use /scratch (200TB 8GB/s), /home is for job preparation only
## do not start jobscript in /scratch but change to it to use massive disk-I/O
## (conflicting link@master vs. mount@nodes), see website for more info
#mkdir -p /scratch/tmp/${USER}/01 # create directory if not existing
#cd /scratch/tmp/${USER}/01;echo new_pwd=$(pwd) # change to scratch-dir
#
# --- please comment out and modify the part you will need! ---
# --- for MPI-Jobs and hybrid MPI/OpenMP-Jobs only ---
# prepare debug options for small test jobs
## set debug-output for small test jobs only:
[ "$SLURM_NNODES" ] && [ $SLURM_NNODES -lt 4 ] && mpidebug="--report-bindings"
#
# prepare nodefile for software using its own MPI (ansys/fluent, starccm++)
# self compiled openmpi-programs do not need the nodelist or hostfile
HOSTFILE=slurm-$SLURM_JOBID.hosts
scontrol show hostnames $SLURM_JOB_NODELIST > $HOSTFILE # one entry per host
#
# ## mpirun may autodetect 32 (hyper-)threads as 32 cpus and run very slow
# ## setting it to no more than 16 will result in optimal performance
# ## also activate core binding (some versions will auto set it)
# ## outside slurm you need $MPI_HOME/bin/mpirun or --prefix for ompi-1.10.1
# mpirun -npernode $SLURM_NTASKS_PER_NODE --bind-to core $mpidebug ./mpi_user_app
# mpirun -machinefile $HOSTFILE ./mpi_user_app
# --fluent-- make sure ssh c001 is working without passwd with ssh-key
# fluent -g 3d -cnf=nodelist-$SLURM_JOBID -pinfiniband -mpi=openmpi \
# -t$SLURM_NPROCS \
# -mpitest # MPI-Network-Test 1.3us, 3140MB/s Reduce=43us(2*16)
# -i inputfile # Ansys-CFD-Simulation instead of -mpitest
# # LICENSES: 1node*16cores maximum for teaching license!
#
# --- for multiple Single-Jobs (Job arrays) and multiple OpenMP-Jobs only ---
#
# ## for ((i=0;i<$SLURM_NPROCS;i++));do ./app1 $i;done # serial version
# srun bash -c "./app1 \$SLURM_PROCID" # parallel version
#
# -------------------------- post-processing -----------
. /cluster/apps/utils/bin/slurmEpilog.sh # cleanup
#
- slurm-commands
sinfo # list available queues/partitions
sbatch job.sh # start job (stop using scancel _JobId_)
sbatch -p big job.sh # start big-job (max 140 nodes)
sbatch -p gpu gpujob.sh # non-GPU-jobs only maxTime=4h and 1Node please (if empty)
# # please use for GPU accelerated jobs only
# note: jobs not using GPU may be killed on demand
sbatch -p short job.sh # short test-jobs max. runtime 1h,
# (short upto 9h at night is moved to partition "night" to reduce slurm logs)
# short: please let space for other users (minimize walltime+nodes)
sbatch -p longrun job.sh # if you have no other choice use this, minimize nodes
# only one job allowed, nodes will be blocked for other users a long time
# ToDo: longrun jobs only for authorized projects, 1h limit else
# or think about checkpointing your application
# PLEASE do not flood partitions with your jobs (limit yourself to 10 jobs)
# better collect lot of small jobs to a bigger one, please notice that
# HPC-Clusters are mainly for big jobs which do not fit to single nodes
# PLEASE do not use login node for computations, other users need it
squeue -u $USER # show own job list
scancel -u $USER # cancel all user jobs (running and pending)
squeue_all # gives a better overview (more but compact info)
squeue_all -l # incl. Pending-Reason and Nodes-Allocated (since 2018-03)
- WARNING: no backup of user data!
Zugang/Ansprechpartner
Der Zugang erfolgt aus der UNI-Domain über
ssh
neumann.urz.uni-magdeburg.de (141.44.8.59) mit Ihrem vom URZ vergebenen
Uni-Account.
Der Zugang erfolgt passwortlos mit ssh-public-keys.
Bitte senden Sie mir den ssh-pubkey mit einer Kurzbeschreibung Ihres Projektes
und den Schaetzungsweisen Bedarf an Memory, Knotenzahl und Laufzeit fuer
ihre Jobs per EMAIL. Studenten benoetigen eine formlose Bestaetigung ihres
universtaeren Betreuers, dass von ihnen zentrale HPC-Resourcen
fuer Forschungszwecke genutzt werden duerfen.
Wenn Sie Windows und Excced für den Zugang (grafisch) benutzen,
beachten Sie bitte die Konfigurationshinweise
des URZ.
Bitte beachten Sie, dass unsere Computeserver nicht der Aufbewahrung von Daten
dienen. Deshalb sind die Plattensysteme nur teilweise mit Redundanz
ausgestattet und auf Backups wird zugunsten von Performance und Stabilitaet
verzichtet.
Sichern Sie bitte selbst Ihre Resultate zeitnah und entfernen Sie angelegte
Dateien, um anderen Nutzern genug Speicher fuer deren Rechnungen zur Verfuegung
stellen zu koennen. Danke!
Für Fragen und Probleme wenden Sie sich bitte an
mailto:Joerg.Schulenburg(at)URZ.Uni-Magdeburg.DE?subject=WWW-t100
oder Tel.58408.
Termine/Infos/Planung:
29.10.15 - Lieferung Server-Schraenke
09.11.15 - Lieferung Knoten und Beginn Aufbau Hardware
16.11.15 - Beginn Softwarerinstallation, Austausch defekter Nodes
25.11.15 - bare metal Linpack/HPL benchmarks und Hardwaretests (58kW)
xx.12.15 - storage test 8-9GB/s beegfs
16.12.15 - Lieferung + Einbau Ruecktuerkuehlung
22.12.15 - beegfs and 16 cores/node running (nach storage-Problemen und max 12 MPI tasks/node)
22.12.15 - IB-Anschluesse getauscht um max. IB-Leistung zu erreichen (s. "Probleme" unten)
13.01.16 - Testbetrieb fuer Nutzer (Unterbrechungen und Aenderungen moeglich)
26.01.16 - Kuehlwasseranschluss fertig, Betrieb mit Kuehlung
27.01.16 - Aufbau Regelbetrieb (production mode), Umbau der Partitions fuer verschiedene Nutzerbeduerfnisse
03.02.16 - Performanceverluste Partition "big" (Fehleranalyse)
03.02.16 - node152 configured out for tests, lot of ECC-errors + slow
10.02.16 - spezielle projektspezifische Partition isut_20d_4GB mit 72 Nodes erstellt (s. Projekte)
11.02.16 - set partition big to 2h (ca. 2 days) to allow isut_20d_4GB start
26.02.16 - Umbenennung in Neumann zu Ehren von John_von_Neumann
08.03.16 - fix bad modulefiles openmpi/gcc/64/1.8.4 and openfoam/2.3.1
09.03.16 - add modulefiles ansys/17.0/fluent and starCCM/10.06
23.03.16 - Partition=sw01_short auf 3h begrenzt zum ueben/debugging/Fehlersuche
24.03.16 - fix missing libnuma.so on nodes for modulefile openmpi/gcc/64/1.8.4
30.03.16 - install strace-4.11 (used for debugging, ToDo: rename to debugging)
01.04.16 - X11-forwarding not working (ssh -X neumann), fixed by CV
13.04.16 - fix module openblas/gcc/64/0.2.14+15 from CV (syntax err + missing LIBRARY_PATH + need gcc/4.8.2 on nodes, 0.2.15 only ~parallel(?))
18.04.16 - Partition=sw01_short auf tags 1h begrenzt (09:00, 2h ab 14:00), nachts 6h ab 21:00, 4h ab 03:00, 2h ab 05:00)
21.04.16 - Partition=sw01_short changed: nachts 6h ab 18:00 (user demand) (ToDo: UTC?)
02.05.16 - repeated early MPI-exits because of 2GB old /dev/shm/psm_shm.*-files (please send ideas to fix it)
09.05.16 - ca. 17:00 problem with login node (LDAP-database corrupt)
10.05.16 - service-call, database repair + reboot login-node, all jobs lost
10.05.16 11:00 system up, possible proplem reason: crashing graphical app on login-node, please avoid apps on login-node
please contact the admin if you feel, that your app was causing the crash to find a fix
17.05.16 - compile + install openblas_haswellp-r0.2.15 +cpu-affinity +warmup (only single-thread was installed)
17.05.16 - compile + install openblas_haswellp-r0.2.14 (default installation was 1..2x slower, without +cpu-affinity +warmup)
18.05.16 17:40 kill running zombies from Feb25,May13,May14 on 26 nodes (detected by health-script, reason 4GB-ulimit on login-node?)
19.05.16 - /cluster/apps/ /cluster/modulefiles/ grp-write-permissions removed (please ask the admin to get write permission)
24.05.16 - /home at 85%, please do not use /home for big data, use /scratch/tmp/${USER}/ instead
27.05.16 - install apps/libc/glibc-2.17 + add linux+asm-headers, gcc/4.8.2 works on nodes
08.06.16 - HPC-User-Treffen, Hauptthema: fair job-scheduling benoetigt
08.06.16 - queue urgent reaktiviert (7 Nodes, priorisierte Kurzjobs und passende Fuelljobs, auf Antrag, 1%IMST 2.5%ILM 30%ISUT)
09.06.16 - Uni-HPC-Wiki fuer Nutzer angelegt
23.06.16 - system maintenance needed (shifted to 19.07.16, other problems)
23.06.16 - slurm.Nodes.RealMemory (default=1MB) to 254000MB corrected, allows option --mem usage (please use!)
24.06.16 - please use increasing nice values when starting multiple jobs, partitions modified
10.07.16 - 4TB-disk failed (of 8*(10+2 RAID6) /scratch), speed -6.25% MTBF1=0.56e6h vs. MTBF=1.2e6h
19.07.16 - system maintenance needed (shifted to August, scontrol show reservation)
22.07.16 - 4TB-disk replaced, rebuild stated 12:00 - ca. 17:00, speed -6.25%
22.07.16 - 4TB-disk failed (of 8*(10+2 RAID6) /scratch), speed -6.25% MTBF1=0.23e6h vs. MTBF=1.2e6h
12.08.16 - some nodes show errors ... more infos later
26.08.16 - slow system I/O, controller node out-of-memory by console log + 90% swap ... console-log disabled
05.09.16 - c034 docker crashed by IB-I/O-error, reboot node034
11.09.16 - /home disk full, please use scratch
18.11.16 - node501 (win) after update failed boot POST=b9 (DIMM replaced 15.12.)
15.12.16 - node152 (DIMM replaced), lot of ECC-errors, failed boot + POST=b7
08.02.17 - activation of slurm job+account-logging, sacct + sstat works now (needed for priorization)
13.03.17 - testing new fair-share script (fvst_isut=30%,fmb_ilm=2.5%,imst=1%)
13.04.17 - /home 100% used, 64% after warning per mailing list (6% /scratch)
12.05.17 - fix missing /scratch (beegfs) after reboot
/install/postscripts/cv_install_beegfs uses yum with default repos,
which failes if a repo is gone (fixed by option --disablerepo=\*)
31.05.17 - /home 100% used (571*750MB-core-files removed, /home=85%used
top-home-user=168GB, 10e6 files, please use /scratch/tmp/$USER instead of $HOME)
03.06.17 - 76 nodes not responding, problem with boot postscripts yum
external reposities failing + ldap/nfs database corruption (?)
expected downtimes until Tue 06.06.2017
08.06.17 - 38 nodes without /scratch, expected downtime until 15.06.
boot process failed on external repos, fixed
19.06.17 - Infiniband problem examination with commercial mpi-libs within docker
number of tasks/node limited to below 32 above 34 nodes
number of tasks/node limited to below 16 above 75 nodes
22.06.17 - 8 nodes with bad DIMMs replaced (see sinfo -R)
10 further bad DIMMs will be replaced at end of July
26.07.17 - Infiniband problem examination finished, start updating system
28.07.17 - 4TB-disk failed (of 8*(10+2 RAID6) /scratch), MTBF2=0.8e6h vs. MTBF=1.2e6h
03.08.17 - 4TB-disk replaced + rebuild
01.01.18 - 62 users, +17/y2017 still growing, about 20Mill.CPUh/year
12.01.18 - 3 min clock-skew on corrected, ntp source was not configured
14.01.18 - 82 nodes hanging (nfs4 problem? nfs_revalidate_inode: ... getattr failed, reboot)
22.01.18 - set localtime from UTC, Amsterdam to Berlin
31.01.18 - add openblas-0.2.15_no_affinity (openblas-affinity conflicts with
MPI-affinity and may reduce performance dramatically by
pinning multiple MPI-tasks on the same core of a node)
02.02.18 - Fr ca. 20:00 system in bad state, DoS on NFS, /home was at 100%
05.02.18 - reboot bad nodes (ca. 30), disable sw04_longrun + sw01_short,
please use longrun + short instead (shorter names)
01.03.18 - switching to cpuh-based priorization, low cpuh users priorized
"squeue_prio_cpuh 2018-03" shows monthly cpuh per institution
10.03.18 23:49 slurm partitions were set down to prevent full /home and crash
13.03.18 - partition node ordering simplified (more IB fragment., better mgmt)
add %R to squeue_all -l, adding node info (shorter than before)
slurm.conf CPUS=16 removed, hardware shows 32, reducing error logs
-- plz check that max 16 MPI tasks used for best performance --
14.03.18 - speedup ssh connections by using /dev/urandom instead blocking
/dev/random (blocking was upto minutes after some nodes reboot)
/etc/sysconfig/sshd SSH_USE_STRONG_RNG=0 (crypto is weaker now)
05.04.18 - remount / xfs with noatime,nodiratime should improve responsiveness
12.04.18 - set include/lib-paths in module gcc/4.8.3 to glibc-2.17
(fixing compile errors on nodes)
18.04.18 15:00 cooling unit down, shutdown until 23.04.18
24.04.18 libmng+libpng12 installed on login-node, fix fslview of fsl-toolbox
28.05.18 libXtst installed on login-node, for some mathlab-functionality
12.06.18 modulefiles/python/2.7.12_Keras extended by PYTHON_CONFIGURE_OPTS
19.06.18 modulefiles/matlab renamed, R2018a added
21.06.18 GPU-kernel-module + module nvidia_driver/390 installed (was missing)
23.06.18 15:51 home 80% used, jobs suspended
26.06.18 epilog-script added to kill hanging processes and clean tmp-dir
30.06.18 15:22 home 90% used, all jobs auto-suspended, 01.07. resumed
08.07.18 cmake-3.8.2 installed
15.07.18 15:47 home 90% used, auto-suspend failed, 23:08 disk ok
12.09.18 Reparatur Klimaanlage, ggf. Lastreduzierung durch suspend/cancel
23.10.18 install cmake-3.4.3 + cmake-3.12.3; use: module avail cmake
25.10.18 gcc-4.9.4 installed, needed to compile glibc-2.28, uses glibc-2.17
26.10.18 nvidia-smi usable now, but 1 of 4 GPUs off for unknown reason
30.10.18 gcc-5.5.0 (c,c++ only) installed (build-problems on docker)
13.11.18 gcc-8.2.0 installed (ompi-1.8.4 problem on nodes? ok on login)
11.01.19 bad DIMM identified on node154 (after disable channel interleave,
some testwise DIMM replacement and linpack test-runs with ECC-errors)
18.01.19 re-enable node154, after replace bad DIMM and testing
21.01.19 re-enable node158, after identify and replace bad DIMM using EDAC
22.01.19 re-enable node029, after BIOS BOOT POST=b7, halt, replace bad DIMM
22.01.19 re-enable node168, after identify and replace 2 bad DIMMs using EDAC
24.01.19 re-enable node146, no EDAC error reproduced, please report problems
24.01.19 61 working nodes (36%) show some EDAC errors (correctable ECC memory errors, over 9 months)
21 working nodes (12%) show more than 250000 EDAC errors in sum (nodes to be checked)
after about 16 bad DIMMs (0.6% of 172*16) replaced (15 nodes) meantime,
only 56% of 172 nodes are not affected by memory ECC errors
25 Nodes have 1-4 errors on a single CPU (soft errors?)
DIMMs are vertical (lower sky radiation), CPUs horizontal
27.02.19 please do not flood partitions with jobs (rule: max 10 jobs/user)
05.03.19 node013 job+node hanging (nfs overload?), reboot
05.03.19 node502 non-killable GPU-process since 10.02., noGPU.No4, reboot
05.03.19 node503 GPU.No4=0x82 not available, draining for reboot
06.03.19 node503 reboot, get back GPU.No4=0x82
26.03.19 reduce gpu MaxTime from 44h to 4h (its mainly for GPU testing)
02.06.19 slurm queues stopped, clima fail on 01.06. 16:30, until 03.06.2019
06.06.19 defect 4TB-SAS-disk(R3dsk19) (of 8*(10+2 RAID6) replaced, 12h rebuild
statistics: 4 failing disks of 96 disks / 3.5 years (MTBF=0.74e6h datasheet=1.2e6h)
16.06.19 shutdown for maintenance (power supply) until 17.06.19
17.06.19 problem getting virtual layer (docker/openstack) running, no login possible
21.06.19 openstack/docker disabled, cluster reconfigured, testing mode, new login
24.06.19 nodes enabled, please report problems, new ssh-fingerprints:
ECDSA key fingerprint SHA256:pTxYsStE8JI3VGXVfXn6Bs1c3agnmkpM8DbgDHjGMUw.
ECDSA key fingerprint MD5:0e:26:b4:3b:59:c3:4b:43:8a:54:73:7d:fa:96:e4:78.
ED25519 key fingerprint MD5:e6:b7:df:5f:ab:b9:a2:a3:72:59:b4:63:78:14:f3:1e.
RSA key fingerprint MD5:ed:5f:c5:6c:5e:51:92:08:d2:f7:f3:f0:16:a4:7b:31.
DSA key fingerprint MD5:bf:ad:a2:57:a9:c2:35:13:98:ef:d8:20:c4:07:85:50.
03.07.-23.07. no support (holidays), use EMAIL if urgent
29.07.19 fix priorisation (was not working, missing option since 24.06.19)
21.09.19 python-devel-2.7 installed, python-2.7 + openssl updated
18.09.19 PriorityType=priority/multifactor (old:basic) to fix fairness
problems for external scheduler, new jobs have lowest priority (1) initially
22.09.19 full home-disk and failing disk-monitor (cluster reconfigured)
some outputs lost, please check your running jobs
06.12.19 modified job fairness (new: fairness for users within groups)
13.12.19 mirrored metadata SSD disk failed on storage02, 25% of beegfs scratch data inaccessible
16.12.19 defect INTEL SSDSC2BW480H6 (SandForce{200026BB}, 3.8y, 4TBW) removed from DMRAID1, reboot ok
14.02.20 GPU-node502 dead, hard resetted
14.02.20 out-of-memory on login node because of bad user processes
15.02.20 GPU-node503 4th GPU=0x82 dead, node remotely resetted
18.02.20 mirrored metadata SSD disk replaced on storage02,
rebuild (dmraid -R) segfaults = redundance problem
19.02.20 fuse-sshfs installed (data access)
16.03.20 storage03 beegfs-metadata-SSD-raid degraded (scratch-dir)
defect INTEL SSDSC2BW480H6 (535 series) sdd=480GB to sde=32KB
dmsetup status: 0 890863616 mirror 2 8:32 8:48 6560/6797 1 AD 1 core
SMART 9=34721h=4y 232.Reservd=097 233.Wearout=083 241.W32MiB=107542
reboot storage03 to initialize rebuild with new SSD
storage02 also booted for rebuild on replacment, dmraid segfaults
26.03.20 07:11 login node is crashed because of multibit-ecc-error DIMMB1
followed by nfs-errors, will not be resumed before 27.03.20 ca. 14:00
most nodes need reboots on monday, hanging nfs
30.03.20 reboot nodes to fix hanging nfs+apps,
switch nfs from hard to soft + timeo=3000 (5min)
31.03.20 10:20 room high temperature alarm 33C, automatically handled
nodes switched from 2.4GHz (35.3kW) to 1.2GHz (23.0kW) for 28min
18.06.20 fix bad DIMMs and boot hangs (press F1 to progress ...) of 2 nodes
22.06.20 fix bad DIMM node044, node150 (multiple ECC-errors)
24.06.20 fix bad DIMM node032 (850 ECC-errors/month + Memory_Train_ERR on boot)
07.07.20 fix bad DIMM node041,node093 (10000-18000 ECC-Errors/month or memtest)
13.07.20 fix gcc-5.5.0 openmp (by using gcc-4.9.4 openmp files via links)
fix gcc-4.8.3 on nodes (5.5+8.2 have h-file problems on nodes)
23.07.20 tentatively reducing priority queue "short" equal to "night"
to give both the same chance at night
08.03.21 00:48 /scratch is down, beegfs-mgmtd stopped for unknown reason
08.03.21 11:03 problem identified, beegfs-mgmtd restarted, /scratch is back
11.03.21 OpenMPI-4.1 installed (module load openmpi/gcc/64/4.1)
15.04.21 OpenFOAM-8 installed (module load openmpi/gcc/64/1.8.4 openfoam/8)
18.05.21 12:30 system maintenance, beegfs SSD failure and full root disk
19.05.21 /home moved to separate disk + quota activated, st01 SSD replaced
06.08.21 crashed RAID-controller, errors on /scratch, maintenance mode
20.10.21 beegfs-meta storage01 timeout problems, /scratch down
2nd RAID-1 (Intel SSD) disk of beegfs-meta switched
to a 32KB FW mode, RAID1 degraded and hanging,
replacement SSD ignored for rebuild for unknown reason
01.11.21 storage04 power unit failure detected, no power redundancy
25.11.21 new system ready, about one week for users to transfer data
29.11.21 18:57 beegfs-mgmt-failure "unrecoverable error", fixed by restart,
storage02 AVAGO MegaRAID SAS 9361-8i Cachevault CVPM02 failed,
instead of 0.8 - 1.5 GB/s write per 12 disk-RAID6, only 80 MB/s/RAID6
30.11.21 usage disabled, removing user accounts and data, uptime 614 days
01.12.21 fix slow storage RAID by setting wrcache=AWB (always write back)
07.12.21 dissassembling
10.01.22 dissassembler found some CPUs with unusual damage on the surface
Projekte:
This is a incomplete list of projects on this cluster to give you an
impression, what the cluster is used for.
- SpinPack
- Quantenspinsysteme, exakte Diagonalisierung (bis 30TB, 2300 Cores, MPI/OMP, FNW-ITP)
- CCCM
- Quantenspinsysteme, Coupled Cluster Method (Rechnungen bis 20TB, 2300 Cores, MPI, FNW-ITP)
- HTE13
- Quantenspinsysteme, High-Temperature Expansion, Core-Speedup=3.5*meggieAMD2009 (2-16 C++11-threads on single nodes, 2GB, OMP, FNW-ITP 2016-02)
-
Partikelmechanik/Schuettgutsysteme ILM
-
20Tage-Projekt fuer CFD partition=isut_20d_4GB (4GB/Node, 64-72 Nodes, MPI, FVST-ISUT, Feb2016)
-
Lattice Boltzmann Simulationen, in-house C++-code + Infiniband (MPI, FVST-ISUT, Feb2016)
-
Roentgenfluoreszenz-Computertomographie,
Simulation der Bild- und Dosisentstehung mit Geant4 (IMT-XFCT, 2016)
-
Kristallisation/Strukturbildung (OMP, FNW-ITP, 2016)
-
Computational surface and organometallic chemistry based on ab initio
methods and density functional theory (FVST-ICH, 2016-03)
-
Mehrphasensimulation der turbulenten Partikelquerstromtrennung in einem Zickzack-Sichter (FVST-ISUT 2016-03)
-
Optimierung von Pumpen (FVST-ISUT 2016-03)
-
Fluid-Struktur-Simulation von zerebralen Aneurysmen (FVST-ISUT 2016-03)
-
Koaleszenz und Phasentrennung in mehrphasigen fluessig-fluessig-Systemen (FVST-ISUT 2016-03)
-
in-house DNS code (above 1000 cores, Infiniband) (FVST-ISUT 2016-03)
-
Convolutional Neural Networks, Cuda SW:TensorFlow(Google)/Caffe(Berkeley) (FEIT 2016-03)
-
Dose simulation (radiation exposure, 10d 6nodes, FEIT-IMT until 2016-04-16)
-
Deep Neural Networks (FEIT-IIKT 2016-04)
-
Extended GERDA classifications with autoencoders (FEIT-IIKT 2016-04)
-
speech-based Emotion Recognition using SVMs, acoustic feature normalisation (FEIT-IIKT 2016-06, bis 40 Threads, 3GB RAM, 1-3h, SW: matlab/octave,audiotools)
-
brain activity measured with BOLD signals from fMRI (IBIO 2016-05 - 2017-03, 32GB/node, 100 nodes, 2 Weeks/Job(?) FSL Toolbox )
-
komplexe Feld Simulationen (IMT_EMV 2016-05)
-
MCMC Algorithms for Spectral Density Estimation in Time Series Analysis, SW: R+CXX (IMST 2016-05, Priorisierung fuer 1% Anteil)
-
FEM-Simulationen sowie Renderarbeiten von uECoG-MEAs
(Mikro-Elektrokortikografie Multi-Elektroden-Arrays) (IMOS 2016-05)
-
Koaleszenz und Phasentrennung in mehrphasigen fluessig-fluessig-Systemen. (5-15 cores, 10d/job, FVST-ISUT-LSS 2016-07)
-
Simulation eines Roentgendetektors mit Geant4 zur Optimierung der Konstruktionsparameter und Dosiswerte. (FEIT-IMT 2016-07)
-
Simulation von "excitation contraction coupling" in ventrikulaeren
Kardiomyozyten (FEM, MPI+BLAS 2016-09 FMA-IAN)
-
Lernen von Neuronalen Netzen mittels EEG
und MEG Daten, Frameworks Keras (2016-10 FIN-IKS, GPUs)
-
Entwicklung eines Loesungsverfahrens fuer ein integriertes
Kommissionierungs- und Tourenplanungsproblem (4800*1h, 2016-10 FWW-BWL)
-
CFD Simulationen von 2-phasigen Stroemungen (Fluss-Strom Projekt,
ISUT_LSS 2016-02)
-
Methoden-Kompetenz fuer den automobilen Leichtbau durch hochfesten
Aluminiumguss (ISUT 2016-12)
-
Generating a landscape of neuronal networks determining number of
so-called pioneer neurons in each case (7.5GB/task 96h/job 12nodes/job,
2017-01 IBIO)
-
Tourenplanungsprobleme mit Ruecktransporten und
dreidimensionalen Ladebeschraenkungen (Routing- und Packproblem,
Adaptive Large Neighbourhood Search, C++) (2017-01
FWW_IMS)
-
DFT-Rechnungen, CP2K v4.1 (10GB/task, 2017-01 FMB_IWF)
-
Implementierung zusaetzlicher Laderestriktionen in ein Packverfahren
fuer ein Tourenplanungsproblem mit dreidimensionalen Ladebeschraenkungen
(C++) (2017-05
FWW_IMS)
-
Parallelisierung des Loesens von gewoehnlichen
Differentialgleichungen mit Hilfe des Parareal-Verfahrens
(C++, 1Node 300MB 15min, FMA_IAN 2017-05)
-
Master thesis CFD, OpenFOAM-simulations (IAUT_AS 2017-10)
-
LES Rechnung fuer Verteiler-Stroemung in der Stahlherstellung, SW: StarCCM+
(ISUT 2017-11)
-
Fire Dynamics Simulations, (SW: FDS-6, MPI-lib, FVST_ICH 2017-11)
-
classification of thyroid texture in Thyroid Ultrasound Image,
initial results (pdf) (matlab, IMT/INKA 2017-12)
-
Fire Dynamics Simulations, Masterstudiengang SGA (SW: FDS-6,
MPI-lib, FVST_IAUT 2017-12)
-
Combustion modeling using ANSYS-CFD (FMB_IFME 2018-01)
calculation of the connectivity matrix of EEG (SW: matlab, HW 32GB++,
2018-03 FIN_ITI + MED)
-
Projekt "Minimierung des Situationsrisikos unter
Beruecksichtigung von Unsicherheiten aus Sensorik, Praediktion und
Regelung", Monte-Carlo-Simulationen (OpenMP/ggf.CUDA)
und machine-learning Berechnungen (FMB_IMS 2018-04)
-
mechanical process engineering
(MPI-jobs, MVT 2018-04)
-
Project “Use of prior knowledge for interventional MRI”
(machine learning using neural nets, GPUs, IEP/MEMoRIAL 2018-06)
-
Monte Carlo Simulationen von Roentgenstreuung bei medizinischen
Durchleuchtungen (FEIT_LMT 2018-06)
-
Projekt: "Photonische Prozessketten" mit AVL Fire (FMB_IMS_EMA 2018-07)
-
Projekt: "Untersuchung der Stroemungsgeschwindigkeit innerhalb
einer Bandgussanlage" (ISUT 2018-08)
-
Forschungsprojekt: MEMoRIAL M2.2, Characterisation and
simulation-based development of Engineering Materials
(FEM in Kontinuum- und Strukturmechanik, Phasenfeldmethode, molekulare Mechanik und
Dichtefunktionaltheorie, FMB_IWF 2018-08)
-
Dreiphasenstroemung mit OpenFoam (IVT_MPS 2019-02)
-
Forschungsprojekt: Auswertungen zum Phase-Amplitude-Coupling
zur Analyse intrakranieller Hirnpotentiale bei Parkinsonpatienten,
Bestimmung Signal-to-Noise-Ratio ueber Monte-Carlo-Permutationen
(FME_KNEU 2019-03)
-
Rekonstruktion von Perfusionsbilddaten (FEIT_LMT, 2019-03)
-
Projekt: A Wavelet-Adaptive Dynamical Core for Climate Simulations
(1200CPUh/30d, C/C++/Fortran,
FIN_ISG, 2019-09)
-
Projekt: DeepHealth
(KPSY, 2019-11)
-
Projekt: Lattice-Boltzmann-Simulationen fuer Kristallisationsprozesse
via In-House-SW (FVST-ISUT, 2019-11)
-
Projekt: AuRa, Erforschung und Entwicklung einer Loesung zum flexiblen
Einsatz autonomer Fahrradsysteme fuer Logistik- und
Befoerderungsaufgaben im urbanen Raum (FMB-IMS-Mechatronik, ca. 10
nodes*4d/job, 2020-01)
-
NLP-Project "Real time voice recognition for caring" (FIN_ITI, 2020-03)
-
Ansys HFSS Project "Vermessung und Simulation eines Mikrowellenfeldes
waehrend Trocknungsversuchen" (IVT 2020-11)
-
Project: Abscheideeffizienz von Aerosolen an OP-Masken
(IVT, AG Mehrphasenstroemungen, SW: OpenFoam)
-
Project: Lattice Boltzmann simulation to study invasion process in anodic PTL
of water electrolyzer (IVT/TVT 2021-03)
-
Projekt: ELEMENTIO2 ("Atomistische Beschreibung neuer Materialien zur
Ressourceneffizienten Bestimmung von Prozesseingangsgroessen fuer das
elektrochemische Praezisionsabtragen"), DFT-Rechnungen, siesta-Code und
ReaxDD+ Methode (IFQ 2021-03)
-
Project: Quantenchemische Untersuchung der Reaktivität azylierter
Formen des Delphinidin-3-Glucosid (Myrtillin), (ICH 2021-08)
-
Project: CFD Simulationen von 2-phasigen Stroemungen kombiniert mit
Partikelsimulation - (FVST 2021-09)
-
Projekt: GATEmobil,
Optimierung von Ampelschaltplaenen mittels evolutionaerer Algorithmen
und Verkehrssimulationen (FMB_ILM 2021-10)
- ... and more
Questions and Answers:
- Q: Why not give longer job times?
A: We have already long waiting times, longer job times generate longer
waiting times. Compared to bigger HPCs we have long times (HLRN 12h,
LRZ 48h). Try more paralelism making job faster or implement some
user level checkpointing. If that does not help you need bigger
clusters on other institutions.
Probleme:
The aim of this list is to share knowledge about problems on cluster
administration. If you find this list by web search and you have
similar experience or solutions,
do not hesitate to share your knowledge with us. Thanks.
- Problem dmraid 1.0.0.rc16 (2009.09.16) can not be rebuild a mirror after
reboot and replacing a defect SSD on storage node,
dmraid -R isw_badhccejfd /dev/sdd
gives: ERROR: isw: wrong number of devices in RAID set "isw_badhccejfd_SSD-Array-1" [1/2] on /dev/sdc
Segmentation fault
also RAID was inaccessible after breakdown of one SSD,
beegfs could not access 25% of data until reboot the storage node,
dmraid mirror behaves like always backup only until breakdown,
redundance-work-around: use degraded mode + daily backup (?)
- some external repos configured and used in node-images, causing
problems on node reboots (overload external repos and network
or fatal errors for lost repos),
this is a bad designed HPC configuration by the distributor but can be
solved by building a local repo on master node
- build gcc-8.2 fails within docker on beeGFS (endless make loop, 2018-11),
it runs outside docker on beeGFS, clock glitches? (ToDo: check details)
- (echo 3 > /proc/sys/vm/drop_caches) im Slurm-Prolog-File
wegen Dockercontainer erfolglos. Fluent meckert bei gefuellten Cache
deshalb ueber zu wenig freien Speicher. (ToDo)
- Starting jobs on /scratch causes trouble, because beegfs has different
mount-points on master and nodes. Please start on /home and change
to /scratch within jobscript.
- solved: hanging or crashing intel-5.0.3- or platform-9.1.4.2-MPI
jobs at start if more than about 60 nodes with 16 cores used
(but openmpi or non-infiniband works, about 1000 mpi-tasks and more).
This was because no lspci and numactl was available inside docker
and commercial mpi-libs were using this executables to decide which
driver to use (really true, they fall back without
any warnings on missing executables).
Solution was to include lspci and numactl to the docker-container.
Thanks to CV-support. Errors: "ibv_create_qp()", "psm_ep_open() failed"
-
Congestion problems on the non-blocking network: Because
Infiniband has static routing, any deviation from a uniform network
(down-nodes, management-nodes, transpositions) can cause
congestions on the network and slowdowns up to a factor of 10
(11 edge switches, 6 core switches each 36 ports,
9...10 destinations per uplink).
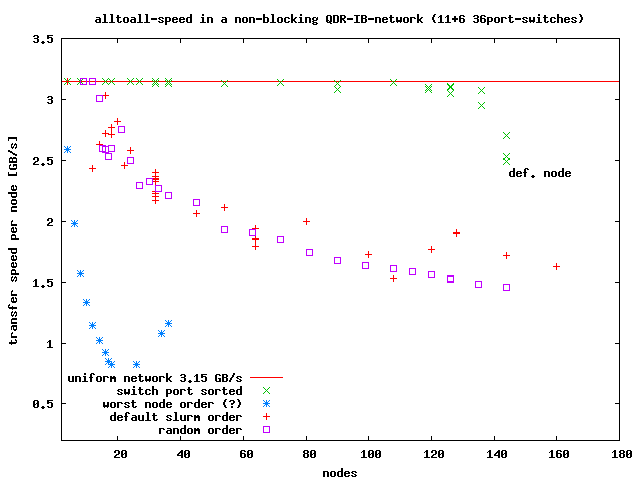
gnuplot-source including experimental data
Sample model:
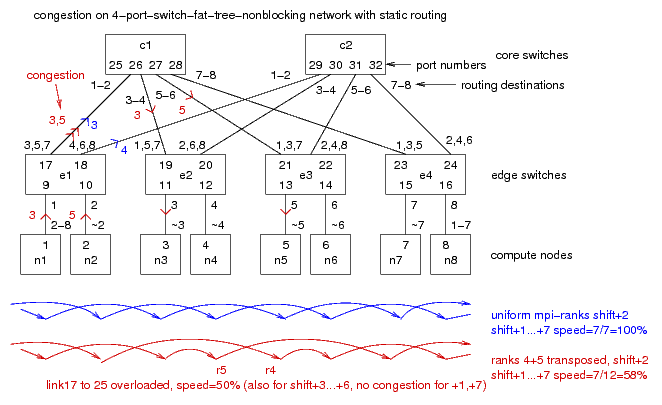
simulation
of congestions in a non-blocking network of 8 nodes and
six 4-port-switches with static routing (bash script, 2015-12).
- After power disconnect the BMC/IPMI (shared_LAN, statische IPv4)
is not reachable per LAN, until the LAN is physicaly disconnected
some seconds after booted System (buggy BIOS/BMC?), than it comes back.
- The BMC processors of the nodes seems to crash somehow after a
longer time or power fail(?), some ipmi commands work, but the
serial redirect seems to hang
("ipmitool ... sol activates" does no serial communication).
After "ipmitool mc reset warm" and 90s waiting serial redirect works
again.
- Sometimes there are thousands of (correctable) memory scrubbing-errors.
I assume, that system (firmware) is detecting bad memory content.
Than it may be corrected written back and fails again if it was not just
radiation induced bitflip but bad memory cells.
Obviously bad (most cases), this memory part should be replaced by spare
memory (not mean spare DIMMs, mean like spare blocks in flash memory or disks,
think DDR4 has this feature too?)
or mark the DIMM as bad somehow to ignore it on next boot and
report the bad DIMM as corrected or incorrectable to the OS/BMC/IPMI.
This should work in every memory mode (interleaving,
scrambling). But id does not. Linux error messages show other error locations
on different BIOS memory configurations (see remark below).
It would be much better to have a (open) way to configure memory ranges
out by the OS regardless of whatever-interleave mode is or/and
let do the OS memory scrubbing.
In all cases such memory errors disappeared after replacing the bad DIMM
or sometimes after putting the bad DIMM to another slot.
But IPMI only reported errors if system was halting in BIOS boot
as described below.
-
BIOS-Option documentation is mostly completely useless, even websearch
shows only links to the useless manuals (2018-03).
Sample: "Halt on mem Training Error" Doc: "Enable or disable halt on mem
Training Error." Thanks to ASUS+AMI, this is really really helpfull, no
explanation about what "mem Training Error" means.
Context: On startup systems with really bad DIMMs just stay on screen
without any helpful output, just a progress bar below the ASUS-Logo
is not progressing at the very beginning
and display on the back shows "b9" or "b7". Why not showing testing memory
XY on screen? Btw. on this condition you can not enter the BIOS
(to disable this halt on error).
Only way is DIMM jogging, get some DIMMs out and try to start.
After log2(NumDIMMs) DIMM changes and test for stay on startup
you have the bad DIMM. This takes about 20min per HPC-node.
And why the hell, does the bios not simply disables bad DIMMs and give
a error report about it later or print an useful message to the screen
before halt, where it is possible to present a logo and progress bar?
Welcome to the 21th century!
(update: looks like configuring to DIMM-interleaving=1x1=no_interleave,
software ce-errors can be mapped to the DIMMs, but wrong indices for
CPU and csrow showed by linux, xhpl as trigger-test
is 11% slower in this mode, update2: disable channel-interleave seems
enough and is 4% slower only, update3: POST=b7 seems related to CPU2,
POST=b9 is related to CPU1 which is not documented but helpful to know,
dmidecode gives serial numbers for DIMMs, but you can not find that
number on the real world label; mem Training seems to be
a kind of connection handshake at DIMM initialization to find best
frequencies and connection parameters I assume
(it is some seconds for 16GB DIMMs and it triggers POST-errors
on bad rank0-DIMMs only),
keywords: EDAC, ECC, bitflips).
- The BMC (system controller reachable by LAN-IPMI) seems to hangup from time
to time in some way. Partly "sol activate" (serial redirection) hangs but
other ipmi commands work or you cant even ping the bmc network.
This is bad for remote administration.
If the linux is reachable it is mostly possible to reset the bmc by local
ipmitool. In some cases a hard power off/on
stops boot and "press F1" message waits at console if bmc can not be
pinged. In that case remote boot is impossible too, but after F1 everything
works (even the BMC lan connection via static IP).
- Serial numbers of the node boards (RS720Q-E8-RS12, Z10PH-D16 Series)
readable by dmidecode are useless.
We have 172 nodes. 5 nodes have no serial number. The others are up to
4-fold. Up to 4 Nodes have the same serial number shown by dmidecode.
All UUIDs differ, except of the 5 nodes without serial number. They have
a dummy UUID build from 123456789. Does dmidecode 2.12 and 3.1 gives correct
output? (detected on 2020 Aug)
...
Weitere HPC-Systeme:
-
5TF 972*4GB MPI-MIPS-Cluster SC5832 kautz(2009-2017),
-
300GF 256GB 32core x86_64 SMP-System meggie(2009)
-
8-GPUs Tesla V100 je 32GB-GPU-Mem gpu18(2018)
weitere Infos zu
zentralen Compute-Servern im CMS
oder im fall-back OvGU-HPC overview
Author: Joerg Schulenburg, Uni-Magdeburg URZ, Tel. 58408 (2015-2020)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}