
outside-Sep21,
night-view,
warm-gangway
|
Sofja - 288 Nodes Infiniband-Cluster (ca. 800 TFLOPs)
News:
- Nov2021 - below our switch-on plan (not fixed yet)
- 24.11.2021 - renaming HPC21 to Sofja
- 24.11.2021 - 67 active users of t100-hpc copied incl. ssh-authkeys
- 25.11.2021 - new HPC21/Sofja system available for users
- 29.11.2021 - switching off old HPC-cluster
Dec2015-Nov2021
- See at History/Timeline for photos of progress
- Jul2022 to Dec2022++ - massive hardware failures
(see history and power-off-problem page)
|
Short description
HPC means "High Performance Computing" (dt.: "Hochleistungsrechnen").
This Cluster "Sofja" is a HPC cluster for universitary sientific use.
It is mainly for parallelized applications with high network communication
and high memory demand, i.e. things which do not fit on a single
workstation.
It is based on linux, the job-scheduler slurm and the MPI library
for the high-speed network.
The HPC-cluster Sofja replaces the older HPC-system Neumann.
Hardware
| Architecture: |
292 infiniband-connected ccNuma-nodes
|
| Prozessor (CPU): |
2 x 16c/32t Ice Lake Xeon 6326 base=2.9GHz max.turbo=3.5GHz(no_avx?)
512-bit-Vector-support (AVX512 2FMA 2.4GHz) 32 FLOP/clock,
3TFLOP/node (flt64), xhpl=2.0TFLOP/node (testrun, 2.4GHz used),
8 memory-channels/CPU je 3.2GT/s 205 GB/s/CPU, 185 W/CPU
| |
| Board: |
D50TNP1SB (4 boards per 2HE-chassis) |
| Main Memory (RAM): | 256 Gbytes, 16*16GB-DDR4-3200GT/s-ECC
Memory-Bandwidth 410 GB/s/Node (4 fat nodes with 1024GB/Node,
partition "fat") |
| Storage (disks): |
diskless compute nodes,
5 x BeeGFS nodes with dm-encrypted 3*(8+2 RAID6) * 4TB each,
ca. 430TB in summary, ca. 2.4GB/s per storage node,
2022 extended to 10 nodes 870TB,
ior-results: home=2.5GB/s (1oss), scratch=10.6GB/s (9oss,1node),
scratch=20.4GB/s (9oss,2nodes)
|
| network: |
Gigabit-Ethernet (management), HDR/2-Infiniband (100Gb/s)
non-blocking |
| Power consumption: | ca. 180kW max. (idle: ca. 54kW,
test 620W/node +max27% cooling) |
| Performance data: | MemStream: 409 GB/s/node, Triad 71%
|
| | MPI: 12.3 GB/s/wire (alltoall uniform, best case)
|
| | Peak = 2460 GFLOPs/node (6.9 FLOP/Byte, 4.0 GF/W)
|
| GPU-nodes: | 15 nodes added around Apr 2022, one GPU-card per node, partition "gpu" |
| GPU A30: | chipset GA100 24GiB RAM 10TF32 F64=1/2, 7 nodes, part of partition "gpu" |
| GPU A40: | chipset GA102 45GiB RAM 37TF32 F64=1/32, 3 nodes, partition "gpu46GB" (45GiB-12MiB) |
| GPU A100: | chipset GA100 80GiB RAM 20TF32 F64=1/2, 5 nodes, partition "gpu80GB" |
Software
- Rocky Linux 8.4, slurm-21.08 (starts your job on the next free time-slot),
Environment-Modules-4.5.2 (to select software and set paths)
- GNU Fortran, C/C++ gcc-8.4, openmpi-4.1
- Before using software please check if usage is covered by the license.
Most commercial software will be for university members or subgroups
only.
These software mostly log its user names and usage on the license server.
- user-managed:
,
(add documentation at
Uni-HPC-Wiki)
- Missing software may be installed by the user. You will get
a writable application directory and help with the module files.
Please ask via EMAIL.
- ATTENTION: Applications which need Floating-Licenses
may abort with failure if there is no free license at
job start. If that is a problem please contact the administration.
- Please use $SCRATCH/$USER/ (beegfs) as storage. Especially
for massive parallel read and writes. It is thought as a temporary
storage during jobs optimized for high throughput.
/home is not intended for high loads and has stronger quotas.
/home is thought as a project time storage.
We have enabled quota to minimize full disk failures for users
not causing it.
Please check your quota before starting jobs. You may get
no output and no error messages if quota is exceeded.
Quota will be checked/updated in a 10 min period.
Default quota values are 400 GB for scratch, 45 GB for home and
300000 for the number of file chunks (at 2024-11).
If you need more, you have to ask the admins for it.
Please always avoid huge number of (small) files because it will
overload filesystem and cause massive performance degradation.
- How to select your compiler or application environment:
module avail # show available Software-Moduls (Compiler)
module list # show loaded modules (also: echo $LOADMODULES)
module load mpi/openmpi-4.1 # OpenMPI
module load ... # libblas + liblapack
# you can put this for your favourite modules to .bash_profile
- Jobsystem: Slurm
- For computations, always use slurm as job manager. It is not allowed
to start computations on the login-node directly, especially to avoid
out-of-memory situations on the shared components of the cluster.
- example jobfile job.sh (copy it and adapt it to your needs)
#!/bin/bash
# please check http://www-e.uni-magdeburg.de/urzs/hpc21/ periodically 2021-11
#
# lines beginning with "#SBATCH" are instructions for the jobsystem (man slurm).
# lines beginning with "##SBATCH" are comments
#
#SBATCH -J job-01 # jobname displayed by squeue
#SBATCH -N 1 # use 1 node
##SBATCH -N 4 # use 4 nodes
# do not waste nodes (check scaling of your app), other users may need them
# since Nov24 jobs using less than 32 cores per nodes share nodes with
# other users
#SBATCH --ntasks-per-node 1 # 1 for multi-thread-codes (using 32 cores)
#SBATCH --cpus-per-task 32 # 1 tasks/node * 32 threads/task = 32 threads/node
##SBATCH --ntasks-per-node 2 # 2 for hybrid code, 2 tasks * 8 cores/task
##SBATCH --cpus-per-task 16 # 2 tasks/node * 16 threads/task = 32 threads/node
##...
##SBATCH --ntasks-per-node 32 # 32 for pure MPI-code or 32 single-core-apps
##SBATCH --cpus-per-task 1 # 32 tasks/node * 1 threads/task = 32 threads/node
##SBATCH --cpu-bind=threads # binding: 111.. 222... 333... per node
#SBATCH --time 01:00:00 # set 1h walltime (=maximum runtime), see sinfo
#SBATCH --mem 80000 # [MB/node], please use less than 120000 MB
##SBATCH --mem-per-cpu 7800 # [MB/core], alternative way, max. 7800 MB/core
##SBATCH --gres=gpu:a30:1 # alloc nodes with one A30-GPU (since Nov24)
# please use all cores of a node (especially small jobs fitting to one node)
#
# most output is for more simple debugging (better support):
. /beegfs1/urz/utils/slurmProlog.sh # output settings, check node healthy
#
# load modulefiles which set paths to mpirun and libs (see website)
echo "DEBUG: LOADEDMODULES=$LOADEDMODULES" # module list
#module load gcc/... # if you need gcc or gcc-libs on nodes, NA
#module load openblas/... # multithread basic linear algebra, NA
module load mpi/openmpi-4.1 # message passing interface
#module load ansys # Ansys-Simulations, License needed!, NA
#module load cuda/toolkit-11.6.0 python/python-3.11.3 # for GPU-usage
echo "DEBUG: LOADEDMODULES=$LOADEDMODULES" # module list
#
# --- please comment out and modify the part you will need! ---
# --- for MPI-Jobs and hybrid MPI/OpenMP-Jobs only ---
## set debug-output for small test jobs only:
# [ "$SLURM_NNODES" ] && [ $SLURM_NNODES -lt 4 ] && mpidebug="--report-bindings"
#
# prepare nodefile for software using its own MPI (ansys/fluent, starccm++)
# self compiled openmpi-programs do not need the nodelist or hostfile
HOSTFILE=slurm-$SLURM_JOBID.hosts
scontrol show hostnames $SLURM_JOB_NODELIST > $HOSTFILE # one entry per host
#
# ## please use $SCRATCH/$USER for big data, but /home/$USER for
# ## slurm output to get error messages in case of scratch over quota,
# ## check your quota before starting new jobs
# cd $SCRATCH/$USER
# mpirun -npernode $SLURM_NTASKS_PER_NODE $mpidebug\
# --map-by slot:PE=$SLURM_CPUS_PER_TASK --bind-to core\
# ./mpi_application
#
# ## for ((i=0;i<$SLURM_NPROCS;i++));do ./app1 $i;done # serial version
# srun bash -c "./app1 \$SLURM_PROCID" # parallel version
#
# -------------------------- post-processing -----------
. /beegfs1/urz/utils/slurmEpilog.sh # output final state, cleanup
#
- slurm-commands
sinfo # list available queues/partitions
sbatch job.sh # start dflt=big,5h job (stop using scancel _JobId_)
sbatch -p short job.sh # small test-jobs, 1h runtime,
sbatch -p medium job.sh # medium size jobs, 2-6h runtime,
sbatch -p big job.sh # big-size-job, max 140 nodes, 5-24h runtime
sbatch -p longrun job.sh # small node subset, 26-49h runtime, plz use checkpoints
# other partitions: short medium big longrun fat gpu gpu46GB gpu80GB
# short overlap medium, medium overlap big, big overlap fat+gpu+longrun
# gpu overlap gpu46GB+gpu80GB, slurm PriorityTier is used to control overlap
# PLEASE do not flood partitions with your jobs (limit yourself to ca.10 jobs)
# better collect lot of small jobs to an "array"-job, please notice that
# HPC-Clusters are mainly for big jobs which do not fit to single nodes
# PLEASE do not use login node for computations, other users need it
# PLEASE use multicore always (32 cores), avoid excessive IO,
# check scaling of your applications (faster if more cores),
# you may be banished from the HPC if you waste lot of CPU resources
squeue -u $USER # show own job list
scancel -u $USER # cancel all user jobs (running and pending)
squeue_all # gives a better overview (more but compact info)
squeue_all -l # incl. Pending-Reason and Nodes-Allocated (since 2018-03)
- WARNING: no backup of user data!
User access:
Access via
ssh
sofja.urz.uni-magdeburg.de (141.44.5.38)
is only allowed from within the universitary IP-range.
As login please use your universitary account name.
It is recommended to use ssh-public-keys for passwordless logins.
Please send your ssh public key together with a short description
of your project, the project time and the GB of storage you probably
need at maximum during your project.
Students need a formless confirmation
of their universitary tutor, that they are allowed to
use central HPC resources for science.
This machine is not suited for work with personal data.
If you use Windows and Excced für for the access (graphical),
take a look to the windows/ssh configuration hints.
Please note that the HPC storage is not intended for long time data
archievement. There is only some hardware redundance (RAID6) and no backup.
We explicite do not backups to not reduce performance of the
applications. So far you are responsible to safe your data outside the
HPC system. Please remove unneeded data to left more space for others.
Thanks!
For questions and problems please contact the administration via
mailto:Joerg.Schulenburg+hpc21(at)URZ.Uni-Magdeburg.DE?subject=hpc-sofja or
Tel.58408 (german or english).
GPU user access:
Since Nov 2024 we have different GPU node management.
As a compromize to the typical usecase (deep learning),
the security concept is different from the rest of the HPC-cluster.
Privacy/Security
- ssh-pubkey (ssh -o visualhostkey=yes -o FingerprintHash=sha256 hpc21b
true) = LN6Q2FMD/1NGovgtsaviz38EQKDYHrQlXLBI89p9Zp8
- network firewall - by default, we allow only intra-net traffic,
and also block all outgoing traffic to
the world-wide internet (except for gpu-nodes).
You have to ask the HPC-administration
to change this if needed. This is to make the cluster more safe against
malicious software (malware)
which often downloads more code or leak data.
- encryption at rest - we use a dmcrypt layer to encrypt the storage to
defend from leaking data by
unerased disks which may leave our computing center (p.e.
defect disk replacement).
This has nearly no impact on disk throughput and small impact
on overall power consumption
(normally much less than 3% of overall cluster power).
Encryption at rest still does not allow to work on personal data
on the cluster,
because disk encryption alone is not enough overall protection
against data leakage.
It still does not fulfill GDPR-requirements for personal data.
But we want to work
on this for some dedicated nodes to give a state-of-the-art
secure technical base (using HW+SW+user+data-separation).
Please contact us if interested.
- ...
History/Timeline:
- Feb2019 - user HPC Meeting about HPC successor (memory bandwitdh needed)
- Jan2020 - DFG proposal 91b, HPC-cluster
- Mai2020 - timeline to rebuild building G01 2022-2023 for HPC
- Oct2020 - DFG acceptance (50% DFG, 50% LSA)
- Feb2021 - HPC tender offer
- May2021 - HPC tender decision (NEC)
- 04.08.2021 - groundplate for the container module made of concrete,
Photo of baseplate Sep2021
- 25.09.2021 - delivery of the container module,
delivery, +2 days
outside,
inside
- 29.09.2021 - input power cables
- 30.09.2021 - cooling pipes and power cables
- 07.10.2021 - floor platters delivered
- 11.10.2021 - a temporary cooling unit
because of supplier problems
- 11.10.2021 - racks delivered
- 12.10.2021 - racks installed
- 22.10.2021 - container and racks ready
- 26.10.2021 - delivery of hpc nodes
- 29.10.2021 - hardware powered on, UEFI-shell (active polling?) ca. 90kW,
BIOS reconfiguration
- 02.11.2021 - linux booted, ca. 45kW idle, checking some bad nodes
- 03.11.2021 - firmware updates
- 01-05.11.2021 - planned: system software installation/configuration
- 08-12.11.2021 - planned: tests/benchmarks and turn over to OvGU
- 11-15.11.2021 - fixing problems, renaming nodes (shorter names)
- 16.11.2021 - add kerberos password support (sssd did not work, use sshd)
- 17.11.2021 - renaming slurm ClusterName to hpc21, add + test beegfs quota,
environment-modules configured
- 18.11.2021 - cluster named Sofja in honor of Prof.
Sofja Kowalewskaja
- 25.11.2021 - hpc available for users (testing phase),
about one week for users to transfer data from
old HPC
- 29.11.2021 - fix beegfs-quota (lost on reboot), over quota jobs without output
- 01.12.2021 - openblas-0.3.17 installed (module load openblas/0.3.17)
- xx.12.2021 - add firewall, no worldwide in+output by default (security)
- 10.01.2022 - slurm config corrected (SelectType=select/linear was cons_res),
slurmd on nodes restarted
- 10.01.2022 - add script quota_all (/usr/local/bin/quota_all)
- 14.01.2022 - cmake, autoconf, git installiert
- 24.01.2022 - add loadavg and infiniband stats to slurm{Pro,Epi}log.sh
- 25.01.2022 - add /proc/stat cpu.user,nice,sys,idle to slurm{Pro,Epi}log.sh,
loadavg may be misleading, %cpu=user/(32*time*100)
- 16.02.2022 - 9-13h downtime, maintenance, beegfs/storage-expansion, 13:25 normal operation
- 16.02.2022 - slurm reconfiguration, overlapping partitions, add PriorityTier
- 16.02.2022 - node cn155 power on failed per ipmi or button, node unplugged to hard reset it
- 23.02.2022 - valgrind + gdb installed on login nodes
- 16.03.2022 - 2d downtime, infiniband cable replacement for storage extension
- 17.03.2022 - storage tests, home=2.5GB/s, scratch=20GB/s (above ca. 50 files)
- 23.03.2022 - reconfiguration network extension for additional gpu nodes
- 09.05.2022 - downtime due to slurm security update
- 13.05.2022 00:15 - blackout PDU3b ca. 1/16 = 6.25% Nodes down, high RCM 30mA-FI
- 19.05.2022 11:50 - blackout PDU3b ca. 1/16 = 6.25% Nodes down, RCM again,
3PSUs moved to PDU3a, ca. 0.4mA-RCM-AC/PSU, 3PSUs/QuadNode(10A), 6*16A/PDU,
ca. 7mA-RCM-AC/PDU, unknown RCM at over-voltage-protector, unknown 30mA-FI sensitivity
- 14.06.2022 - hdf5-1.12.2 installation, cxx and parallel(mpi) version, mpi check failed
- 17.06.2022 - node cn001-012 reset by admin mistake
- 19.06.2022 - node cn155 crashed by kernel panic, testing memory
- 20.06.2022 - node cn155 memtester finds 64Bytes not written(!)
more and more often at random positions,
cache-line-problem? cpu-aging?
- 26.06.2022 - node cn155 three successive reboots crash at kernel load
- 29.06.2022 - node cn041 spontaneous powered off (BMC logged it),
power on failed (BMC logged failure too)
- 07.07.2022 - node cn155 replaced, died with more freqently crashes
until non-bootable OS (fast aging?)
- 02.08.2022 - cn206 crashed 1st time,
on testing maybe OOM caused kernel panic,
but next 2 reboots paniced at kernel load, BIOS.TurboBoost=off helped,
SOL (serial-over-LAN) mostly disconnects within 40s, BIOS.CPU_C6=off helped
- 04.08.2022 - testing spontaneous powered-off node cn163,
power on failed until node replugged,
SOL disconnects vanish at BIOS.CPU_C6=off,
looks like the BMC has a C6-State problem (?)
- 04.08.2022 - power distribution cabinet triggers Line Leakage Alarm,
this may caused by the sum of leakage current of the node PSUs
and normal fluctuations
- 05.08.2022 - node cn005-016 drained for testing instability workarounds,
SOL disconnects after 20-200s on ~75% of nodes,
cn009 switched off spontaneously at ssh session and ipmi power on failed,
- 05.08.2022 - problem overview: 2-4 nodes
crashed per week with no or random(?) BMC logs since July,
some nodes switched off spontaneously
and can not be switched on without unplugging the hardware,
possible workaround: disable CPU-C6 (against SOL disconnects, maybe
more),
disable TurboBoost (against unrelated crashes and assumed fast aging),
affected slurm jobs will be requeued
- 05.08.2022 -
add node problem reports to this timeline for other admins interested
- 08.08.2022 - disable C6 (cpuidle/state3) on all nodes,
set max_cpu_frequency to 3300 MHz (reduced boost) testing stability, minimum
performance degration
- 10.08.2022 15:10 disallow memory_overcommit (booking more memory
than available) to prevent OOM crashes (test-phase), codes which
alloc more memory than 250GB (but not use it) will be affected
- 11.08.2022 12:40 - nodes cn124 and cn144 spontaneously switched off,
switch on failed (happen on different nodes more often?),
2 140-node-jobs on other nodes crashed with MPI error,
set max_cpu_frequency to 3000 MHz (more reduced oost) for stability testing,
upto 10% performance degration
- 12.08.2022 16 nodes unintended switched off
during frequency-set --max 2900000, some off-nodes still show green power LED
until power on is tried and failed (update: all affected nodes do show
wrong power state LED until remote power on is tried)
- 15.08.2022 further nodes going off on frequency setting, BIOS
update applied to cn001-004, fixing SOL-idle-disconnect problem (update:
problem appeared again),
BIOS update scheduled to all nodes, cluster draining
- 16.08.2022 maintenance, firmware update on all nodes
- 17.08.2022 maintenance, about 10% nodes crash (spontaneous go off)
on idle if max-cpu-frequency is reduced and set back (reproducer),
88 nodes (30%) go off after 3 rounds of reproducer,
5 nodes crash during xhpl which runs on 2.40GHz
- 17.08.2022 noise measurements,
100dB between racks, 97dB outer floors (-3dB=50%), running xhpl,
at about 1000 Amps (230VAC) including all cooling units, 2.0TF/node
(81% peak=2.4GHz*32F*32c) not tuned to maximum
- 17.08.2022 please do not run fat long running jobs
(above 100 nodes) until instability problems are fixed
- 18.08.2022 cn143 runs at ~150MHz, below minimum frequency of 800MHz,
(found dyn.Range=~90-200MHz) xhpl=67GF speed=1/30,
45 min for 3stage-booting,
before the down-clock-event cn143 had the power-off-on-problem 5 times
- 18.08.2022 cn050 unintended powered off (in spite of fmax=2.4GHz
was set),
during MPI_Wait, 15 min later cn019 (same MPI-job) unintended was going off
- 19.08.2022 cn041 runs at ~150MHz below minimum range
since last needed power disconnect
(cn041 was the node with most power-off-on-fail count 10)
- 2022-08-23 cn168 runs at ~150MHz (3rd node),
removing CMOS BAT cn143 does not help to get back normal clock rate,
50 affected slurm nodes down since Aug, 17th (5 days),
until Aug 19th overall 99 Nodes with following error logs:
Power Unit Pwr Unit Status | Power off/down | Asserted
There is no message point to the reason, its like pressing the power
button. But if tried to switch on remotely you get following error:
Power Unit Pwr Unit Status | Soft-power control failure | Asserted
since BIOS update this is followed by next two lines
Processor P1 D1 Status | Thermal Trip | Asserted
Processor P2 D1 Status | Thermal Trip | Asserted
- 2022-08-29 to 2022-08-31 stability tests, user jobs may crash
- 2022-08-31 two nodes cn279+cn280 booted at 100-200MHz (4th+5th node)
- 2022-08-31 new microcode installed on rack6-8, no unintended power-off (3 test rounds)
- 2022-09-01 microcode update on rack1-5, revision=0xd000363 2022-03-30,
testing fmax=800MHz, fmax=3500MHz let 32 of 292 nodes fall off immediately,
problem persist
- 2022-09-05 cluster still needs maintainance to localize the problem
- 2022-09-09 4 nodes cn085-088 run at ~150MHz with failed power supply PS3,
back to normal frequency range after (defect) PS3 removed
- 2022-09-14 cn277-280 switched to ~150MHz mode by reboot and can not be
set back similar to cn085-088, they also run at ~150MHz in other slots
- 2022-09-15 because of the bad situation, JobRequeue is disabled,
new partitions "test" and "instable" are added, "big" is reduced,
"test" is usable but no drain states (72-144 nodes),
jobs may be simply killed if
testing capacity is needed Mon-Fri, "instable" is for bad nodes (150MHz,
instable infinband/storage etc., some may somehow usable, use --exclude
or --nodelist options),
please report reproducable failures
- 2022-09-18 discovered cn260 running at 800MHz maximum speed
(may be a result of longer FIRESTARTER testing)
- 2022-09-19 3 nodes with unintended power off over weekend (at idle state)
- 2022-09-20 4TB disk failed at stor01, replaced by onsite cold spare
- 2022-09-26 maintenance Infiniband/Storage, IB FW-updates, reboot
- 2022-09-26 ca. 18:15 mpi/beegfs disconnect/timout problems
with cn093-cn107 fixed (ip address conflict ipoib to 15 new gpu-nodes)
- 2022-09-27 kernel panics at cn171 (4h after boot) and fat03 (at boot),
10:00 set fmax=2000MHz (-20%), c6=off, turbo=off, governor=powersave to minimize HW
failures
14:57 iptables incl. NAT fixed (needed for external license servers)
please report hardware/mpi failures and single slow nodes
- 2022-09-30 set fmax=1800MHz over weekend to check failure rate
- 2022-10-01 cn244 unintended switched off (600 old PS1 failures logged),
cn245 showed 800MHz speed only (same 80node-job and switched off 4d
later at another 32node-job)
- 2022-10-05 for 6 days 7 nodes with unintended power off at fmax=1800MHz
- 2022-10-10 for 5 days 5 nodes with unintended power off at fmax=1800MHz
- 2022-10-10 BIOS update 1.0.6 for Rack2+3 (cn037-108),
10 nodes ~150MHz after 45min reboot (cn[042-044,069-071,103,105,107-108]),
- 2022-10-11 10:30
after power line disconnect (to reset ~150 MHz nodes)
CPUs of 11 nodes found at ~150MHz
(cn[042-044,069-072,103,105,107-108]=30.5% of Rack 2+3),
bad ~150MHz nodes removed from big/test/short-partitions
- 2022-10-11 10:15 Rack 5 (cn145-cn180) rebootet accidentally in
preparation for power line measurements at test-queue,
2 new nodes (cn165-166 at 150MHz after boot, 15 150MHz-nodes in sum)
- 2022-10-12 try to get back cn277-280 from 150MHz by pulling
1 of 3 power supplies, no success
- 2022-10-18 report to ZKI-AK-SC conference
- 2022-11-02 150MHz-problem fixed per ipmi raw command
for cn042-044 cn277-280 ... (14 nodes), thanks to hpc.fau.de fellows
- 2022-11-03 11-16h planned system maintainance, slurm reconfig
partitions due to failed nodes,
~10 further slow nodes above 800MHz found and fixed per ipmi raw
- 2022-11-09 4 replacement boards for often-failed-off-nodes delivered
and used to replace cn243-245,cn199, Intel support is able to reproduce
low-CPU-clock-problem, ipmi raw command should reset bad ME register,
still no solution for power-off problem
- 2022-11-16 10-16h planned system maintainance, BIOS update,
apply low-CPU-speed-fix/workarround
- 2022-11-17 23 nodes failed with off during BIOS update, 2
of them failed for the first time, one had a OS crash
- 2022-11-24 12 unintended power offs for the past 7 days
(mode: powersave no_turbo no_c6), sorting good and bad nodes seems to
be an improvement, 3 known job-crashs on the good nodes by mistakes,
12 known job crashes caused by bad nodes going off; one low-frequency
problem (fmax CPU1 1300MHz, CPU2 800MHz) in spite of ipmi-raw fix (but
performance mode, turbo and c6 enabled accidentally)
- 2022-12-07 11 unintended power offs for the past 7 days,
6 replacement boards for bad nodes,
cn163 cpu replaced (same issue as cn155 07.07.2022,
may be same CPU on replacement node),
cn288 with low speed (fbase CPU1 800MHz, CPU2 2600MHz) ME-reset by jumper
with same result as ipmi raw fix (ME VR register read failure, new boards
return 64, old boards return 00 originally or failure after ME-reset)
- 2022-12-09 support identified power supply version 00A as problem
source, replacement by newer model planned for Jan2023
- 2022-12-12 power supply failed + 16A fuse triggered on test,
leading to cn113-116 powered off
- 2022-12-14 8:30 Wednesday: system downtime for quotacheck
(check failed at last boot 2022-09-26, wrong numbers)
- 2023-01-02 since 2022-12-24 (10d) 39 nodes with unintended power-off
(mainly 2 waves with 12 nodes each within seconds at 12/26 and 01/02,
one node failed for first time),
1 node paniced, 1 slurm-fail, after replug 3 nodes with low clock, 5 nodes
with power supply sensor failures
- 2023-01-16 7 unintended power off nodes and 1 uncorrectable
ECC-panic for the last 11 days, one of the 7 off-nodes had a new
board from replacement (but old CPUs and DIMMs)
- 2023-01-16 today 6 nodes fell off, initially one big job (with
~10kW power oscillation, 72 nodes) caused
1 node to go off after 6h regulary computation,
but 7min later (slurm timeout)
5 other small jobs killed 5 further nodes at startup,
that means the power off-problem has very likely a kind of memory,
setting test partition (~100 nodes) to 1500 MHz CPU clock (52%)
- 2023-01-20 about 15 bitflips detected on 7 (2.4%) random nodes
in ipmitool fru coming from power supplies (mostly bit7 0-to-1),
changing after "bmc reset cold",
maybe correlated to incorrect short 63 C over temperature,
14.06 V over voltage and thousands of Fan-failure alarms
coming from the power supplies logged in the system error log (SEL)
- 2023-01-23 downtime, 219 power supplies replaced (newer model version)
having same bitflip issue as old once
- 2023-01-25 10 nodes with unintended power off, 2 other crashes
(uncorrectable ECC error, Prozessor Internal Error (IERR)) within 50 hours,
repair trial was not a success, big jobs failed to finish
- 2023-01-27 1 node with unintended power offs
- 2023-01-29 11 nodes with unintended power offs
- 2023-01-31 6 nodes with unintended power offs
- 2023-01-31 2*18 Nodes replaced, check if power-off-failure moves
- 2023-02-02 downtime, Firmware Update 07
(failure related, with "additional bit error optimization")
- 2023-02-06 still failures, less (or no?) PS Fan failure LOGs
- 2023-02-08 2*18 Nodes placed back after 8 days,
4 unintended power offs within moved 18 "bad" nodes (on-board problem?)
- 2023-02-10 downtime Rack02, Firmware Update - debug version
- 2023-02-13 or later, more downtimes for debugging by support
- 2023-02-14 off-nodes power on automatically, still power offs,
statistic updated
- 2023-03-03 maintenance planned (BIOS update)
- 2023-03-17 BMC-FW update cn001-cn144 debugging
- 2023-03-20 8 nodes with failure within cn145-288 and
no nodes failed within cn001-144
since updated (2 days)
- 2023-03-20 report to ZKI-AK-SC conference planned (deferred)
- 2023-03-21 BMC-FW update cn145-cn288,fat01-fat04,
still no failes on cn001-144 (3 days)
- 2023-03-28 no failed nodes after BMC-FW update (7 days),
partitions reconfigured, test-partition closed
- 2023-04-09 no failed nodes after BMC-FW update (19 days)
- 2023-04-10 18:40 cn014 crashed uncorrectable ECC error
- 2023-04-19 16:00 firewall rule fix, block traffic to worldwide network from nodes
- 2023-05-09 12:00 add "medium" partition for max. 6h time limit,
the medium queue is intended to fill (backfill) gaps
with lower priority jobs to increase overall usage to above 85%;
gpu nodes added to other general partitions too (filled at last);
default time limits increased according to other partition limits
(from 1h to 2 or 5h)
- 2023-05-09 14:15 - 14:30 failure cooling system, safety power off
- 2023-05-10 15:25 back to operation mode
(problem is auto-on of nodes 50 min after shutdown,
caused by the debugging firmware of Feb/Mar23, unwanted on cooling failure)
- 2023-05-11 15:40 power failure 2x35A fuses Rack5b L1+L3 for unknown reason (max. 20A load)
- 2023-05-12 09:15 power failure Rack5a L1-L3 by mistake
- 2023-05-12 ~14:00 maintenance, fix storage quota, CPLD FW updates
- 2023-05-22 ~03:49 cn169 crashed because of Uncorrectable ECC Memory
- 2023-06-12 ~16:42 cn151 shutdown by URZ-over-temperatur-script
triggered by bad BMC sensor data "BB inlet" 48C (usual 22C)
- 2023-06-23 10:20 failure cooling unit,
automatic low power mode (800MHz cpufreq), auto-all-power-off avoided by
cooling unit reset, but 8 nodes 38C-auto-off-script
- 2023-06-30 module cuda/toolkit-11.6 python/python-3.11 tested
- 2023-07-11 15:38 cpu-power reduced to 1200MHz=41%
to relieve the cooling unit
(power reduction from 160kVA to 100kVA=62%, temperature back to normal),
testing different frequencies later, 2000MHz=69% 116kVA=72% over night
- 2023-07-12 14:09 cpu-power reduced to 2700MHz=93% to stop rise
of cold water temperature (power reduction from 160kVA to 134kVA=84%(?))
- 2023-09-08 15:24 8 min cooling failure, 1/4 compressor down (?),
cpu-power reduced to 1800MHz=62% (power 100kVA), 30C-weather+sun
- 2023-10-13 17:00 30 min cooling failure,
automatic emergency shutdown at 33/37 C (cold/warm side air,
normally 19/31C), 31/33C (fluid, normally 13/18C)
- 2023-10-16 14:05 slurm resumed
- 2023-11-02 12:42 UTC cn162 spontanious reboot, Uncorrectable ECC logged
- 2023-11-29 13:45 UTC cn046 Uncorrectable ECC logged, node survived
- 2023-12-13 14:10 UTC cn194 Uncorrectable ECC logged, node survived
- 2023-12-28 13:48 UTC cn032 kernel crash, Uncorrectable ECC logged
- 2024-01-17 14:00 cn042 accidentally resetted by administration
- 2024-01-18 cn046 Uncorrectable ECC triggered immediately by memtester,
repeatable after reset (3x), disappeared after power cycle, similar for
cn032 and cn162, partly reset was ignored until mc reset (buggy FW?),
cn194 UECC could not be triggered by memtester (one-time-shot)
- 2024-01-27 Sa 05:09:14 UTC cn001 spontan reboot, idle, IERR
- 2024-03-01 Sa 02:20 CET 40 min cooling failure,
automatic clock-down to 800MHz at 29C at t+40min
- 2024-03-04 Mo 14:11 CET cn248 CPU0.C1 Uncorrectable ECC + crash,
2 earlier UECCs Feb19+Feb24 killed big Jobs
- 2024-03-11 Mo 98:32 UTC cn159 CPU0.B1 Uncorrectable(?) ECC +
crash, reset crashes the BMC
- 2024-03-15 Fr 13-15 update cuda/driver gpu-nodes cuda-12.4
- 2024-03-29 Fr ~11:20 power unit failed, fuse triggered, Rack4,
gpu06,cn[109-112,117-120,125-128,133-140]
- 2024-04-02 Di fuse resetted, defect power unit identified
- 2024-04-22 Mo 10:39 CEST cn220 CPU0.A0 Uncorrectable(?) ECC +
crash (reproducable by mem-checker at first mem-touch and boot-crashes,
often seen on other nodes very similar, fixed after DC power disconnect,
assuming another hardware/firmware problem)
- 2024-05-21 602 days uptime (login node), 927 days (master node)
- 2024-05-23 node cn110 temperatur sensor failure (-25C instead of +25C),
this may be a problem if alarms and power off would be triggered by wrong
values (1 error of about 86000 sensor readings per node within 4 months)
- 2024-05-26 18:49 node cn194 CPU0.E1 Uncorrectable(?) ECC + crash
- 2024-07-22 maintenance cooling unit (4 days)
- 2024-07-23 maintenance cooling unit (3 days), power reduction ~25%
- 2024-09-18 pressure loss at cooling circuit, defect valve at expansion vessel replaced
- 2024-10-11 node gpu01 A100 removed, node gpu02 A100 added, now has 2*A100 (test)
- 2024-10-29 access to world-network enabled for gpu-nodes only, no icmp
- 2024-10-30 GPUs reordered: gpu01=A100 gpu02-03=2*A100 gpu04=2*A40 gpu05=A40 gpu06-08=2*A30 gpu09=A30
- 2024-10-30 Gres-Allocation is in progress, meantime please use sbatch option like
--nodelist=gpu02,gpu03
- 2024-11-04 Gres-Allocation configured, but needs reconfigure SelectType=select/linear
to select/cons_tres
- 2024-11-07 09:20 reconfiguration Slurm.SelectType=select/cons_res,
allow shared resources
by "--gres=gpu:a30:1" (one A30-GPU per node) or "--gres=gpu:a30:2" (2 A30-GPUs per node)
- 2024-11-12 maintenance cooling unit (3 days), power reduction to ~25%
- 2024-12-05 14:31 UTC node cn164 unexpected off, node defect
- 2024-12-06 planned: maintenance cooling unit, power reduction to ~25%
- 2025-01-17 22:19 UTC node cn145 unexpected rebooted, caused by UECC error
- 2025-01-28 19:50 UTC node cn281 unexpected crash, no SEL entry
- 2025-02-21 19:00 UTC node cn231 unexpected rebooted, caused by UECC error
- 2025-02-25 09:22 UTC node cn025 unexpected rebooted, caused by UECC error
- 2025-02-26 Rack1+2 restore CPUs to max2700MHz from 800MHz lowpower mode
- 2025-03-08 00:19 UTC node cn167 logged CECC + panic, reboot+memtest=12*UECC,
off+on=crashBMC, mc_reset=OK (looks like crashed BMC, appears most often)
- 2025-03-19 git-lfs, sqlite3 for python3.10 installed
- 2025-04-01 fix wrong valgrind_lib-path for module rh8 (noAVX512-support, use march=skylake)
- 2025-04-07 16:28 short time power outage (campusweit), most(?) compute nodes down
- 2025-04-08 planned check and power on, shift +1 day
- 2025-04-19 16:18 node cn057 unexpected reboot, watchdog2 triggered, pre-outage false positive fan failures
- 2025-05-04 13:48 UTC node cn265 unexpected rebooted, caused by UECC+CECC errors, fixed by MC reset
- 2025-05-05 06:35 node fat02 unexpected power off, false positive fan + later 12.0V failures within quad-blade, MC reset
- 2025-05-05 planned: maintenance cooling unit, power reduction to ~25%,
5 days
- 2025-05-12 Rack 8 PSU cn233-237 failed, 3 16A-fuses triggered
- 2025-05-12 12:16 node cn157 unexpected reboot, false positive fan failures within quad-blade, MC reset
- 2025-05-12 16:05 node cn280 unexpected reboot, false positive fan + 12.0V failures within quad-blade, MC reset
- 2025-05-13 GNU screen potential suid-vulnerability fixed
- 2025-05-27 09:42 node cn198 unexpected power off, SEL overwritten by 4000+
false positive fan failures, stopped by MC reset of cn197 (1st blade)
- ToDo: TMPDIR, GRES:GPU.,
CUDA Multi-Process Service (MPS) on 3 gpus,
pam-slurm, job-priorization firewall kernel-params
SW:charliecloud ...
(config lower bill for low prio jobs (medium, short))
Projects:
This is a incomplete list of projects on this cluster to give you an
impression, what the cluster is used for.
- SpinPack
- Quantum spin systems, exact diagonalisation (sparse matrix,
scaling tested for 3000*16 Cores, hybrid-code MPI/OMP, FNW-ITP)
- ca. active 65 users and its projects from
the predecessor
-
RETERO - Simulation einer Fischabstiegsanlage, um Schaedigungsrisiko
passierender Fische zu analysieren. Die Simulationen beinhalten eine
Wasserjet-Mehrphasenstroemung mit injizierten DEM-Partikeln und
anschliessender Kolissionsauswertung.
(LSS 2023-01)
- KI-Inspire Monte Carlo Simulationen mit dem
geant4 Toolkit GATE (2023-02 IMT)
-
LBM simulations (2024-06 LSS)
-
Quantentheoretische Rechnungen am Lehrstuhl fuer Chemische Verfahrenstechnik
(2024-06 IVT-CVT SW: orca)
-
statistical reconstruction of X-Ray Fluorescence Tomography employing Monte
Carlo Methods (2024-07 IMT)
-
Simulation und Training von Deep Reinforcement Learning Agenten in
Agentensystemen der Produktion und Logistik (ILM/FMB, 2025-04 - 2028-04)
-
ML to search for a directed edge polytope that has
the integer decomposition property and whose h^*-vector is not unimodal,
to answer the Ehrhart unimodality conjecture
(IAG/FMA 2025-07 - 2025-10)
- ... and more
Questions and Answers:
- Q: Why not give longer job times?
A: We have already long waiting times, longer job times generate longer
waiting times. Compared to bigger HPCs we have long times (HLRN 12h,
LRZ 48h). Try more parallelism making job faster or implement some
user level checkpointing. If that does not help you need bigger
clusters on other institutions.
Problems:
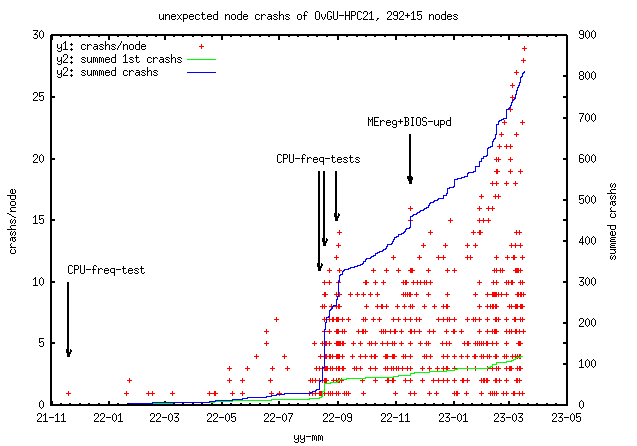
Aug22: after ~8 months usage, lot of nodes (~100)
with unintended power off
and failed power on until power removed,
3 nodes boot with CPU clock below 230MHz, instable MPI-processes for
big jobs (88-140 Nodes (partly fixed at Sep)),
LOGs about Fans (some have thousands), PSUs, ECC-UE (uncorrectable
errors and no or seldom CE-errors), ECC-CE (correctable errors),
false BB Voltage Readings of 14.06 V on 12V line,
false PSU Temperature Readings of 63 C or 127 C (clearly outriders),
2 total failing nodes showing above signs before (one showed aging),
seems to be random kind of error messages (at some fail state?),
seems to become much worse with time (off-problem),
seems dynamic clock related (off-problem), changing fmax on all nodes
mostly produces power-off failures on some nodes
(power-off problem fixed 2023Q1 by FW update, but still
thousands of false positive (fake) sensor errors most for fan1,
some UECC or over voltage). Seems to be related to the quad-blade
structure.
Sep22: after CPU fmax changes, found some power supplies (PS) or its sensors
go to fail state, ususally they come back by "mc power reset" of 1st node,
2 power supplies died,
one failed PS3 caused all 4 connected nodes to run
below 230MHz until PS3 removed
and nodes replugged,
still to much jobs failed because of failed_node,
some nodes (3)
found speed limited to 800MHz or above but slower than the rest,
some jobs hang with MPI communication after about 10-12h normal
processing until timeout (speed fixed at Q1 2023 by FW update,
PSU/PMBus issue partly improved but not fixed)
Oct22: found gpu-nodes bmc not reachable, if node switched off, that means
they can switched off but not switched on remotely (fixed Q1 2023)
Oct22,20th: 18 nodes (6.2%) run below 230MHz
(below minimum CPU clock of 800MHz, shown by /proc/cpuinfo),
this looks Quad-related because
they are grouped to 6 of 72 Quads (8.3%) by 3 + 4 + 1 + 3 + 3 + 4 nodes.
4 nodes of each Quad have the same 3 power supplies (2+1 redundancy, 3*2kW).
Speed is 20 to 45 times slower (p.e. 45 min boot time, md5-speed is 45x
slower pointing to 53 MHz effective CPU clock).
4 nodes (not counted above) could be brought back to normal speed by
disconnecting the Quad from power. This did not work for the above nodes.
(temporay fixed Q4 2022 by ipmi raw cmd,
and overcurrent cause fixed Q1 2023 by FW update)
Design-problems:
- 3 PSUs per chassis fits badly to 2 PDUs per rack, especially when there
is no strong powercapping in case of a failed PDU
Further HPC-Systems:
-
5TF 972*4GB MPI-MIPS-Cluster SC5832 kautz(2009-2017),
-
300GF 256GB 32core x86_64 SMP-System meggie(2009-2020)
-
8-GPUs Tesla V100 je 32GB-GPU-Mem gpu18(2018)
-
172 nodes (16c/256GB) 40Gb-infiniband compute cluster "Neumann" t100(2015-2021)
more infos to
central HPC compute servers at the CMS websites (content management
system)
or at the fall-back OvGU-HPC overview
Author: Joerg Schulenburg, Uni-Magdeburg URZ, Tel. 58408 (2021-2026)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}